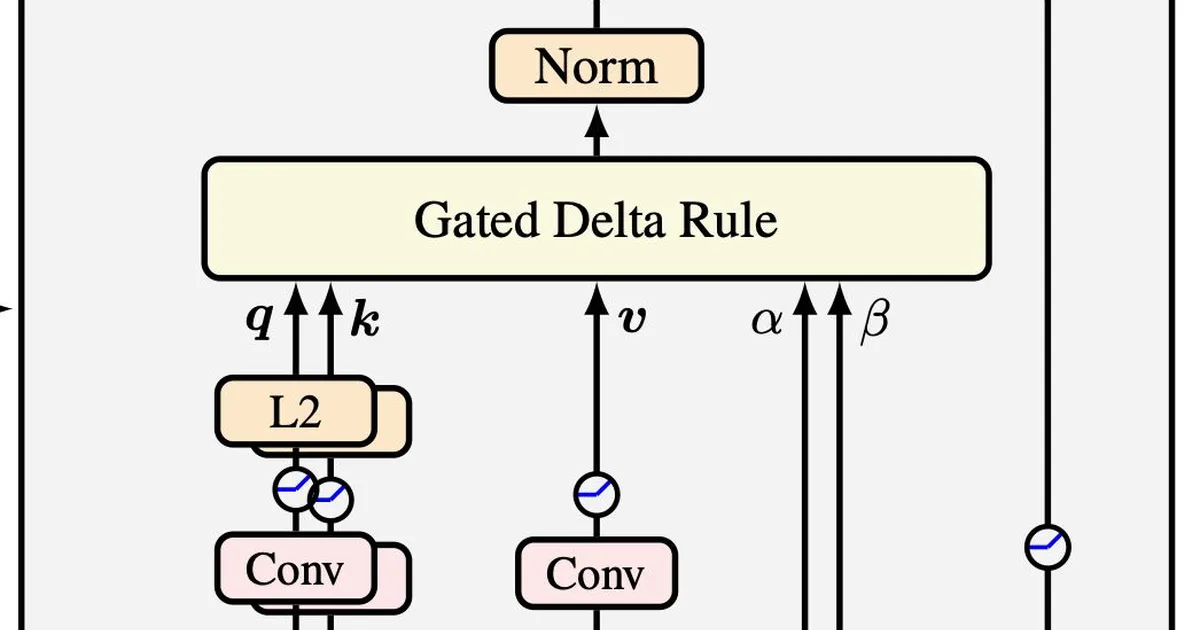
The Transformer architecture's attention mechanism has seen significant evolution since its inception, with numerous advancements contributing to more efficient and capable large language models. Innovations like FlashAttention, Multi-Query Attention (MQA), Grouped-Query Attention (GQA), and Sliding Window Attention (SWA) have drastically reduced memory requirements and improved inference performance. More recent developments, including linear attention variants like Gated Delta Networks (GDNs) and sparse attention methods such as Native Sparse Attention (DSA), are pushing the boundaries further, with many open-weight models adopting these techniques. AI
IMPACT These advancements in attention mechanisms are crucial for improving LLM efficiency and enabling longer context windows, directly impacting model performance and accessibility.
RANK_REASON The cluster details advancements in attention mechanisms for Transformer models, including specific techniques and their adoption in open-source models.
- Alibaba
- Attention
- DeepSeek
- FlashAttention
- Gated Delta Networks
- GQA
- Grouped Query Attention
- Kimi Delta Attention
- LLaMA
- Meta AI
- Mistral AI
- Multi-Query Attention
- Native Sparse Attention
- Noam Shazeer
- Qwen 3.5
- Sliding Window Attention
- Songlin Yang
- Transformer
- Tri Dao
AI-generated summary · Google Gemini · from 8 sources. How we write summaries →