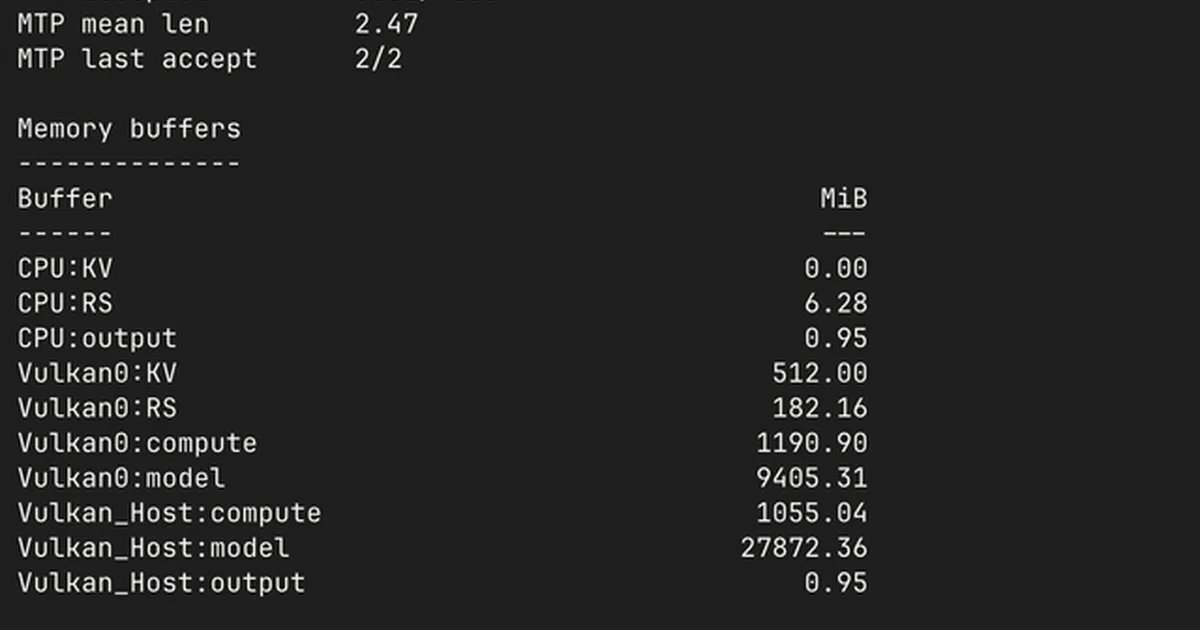
A user has developed a script to monitor and analyze the memory usage of llama.cpp, a popular inference engine for large language models. This script parses the verbose output of llama.cpp to provide a clear summary of buffer allocations, memory requirements, and performance metrics like tokens per second. The goal is to help users with commodity hardware better understand and predict the VRAM and RAM needs of various models, especially when using different quantization levels. AI
IMPACT Helps users optimize hardware usage for running LLMs locally.
RANK_REASON User-developed script for a specific software tool.
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →