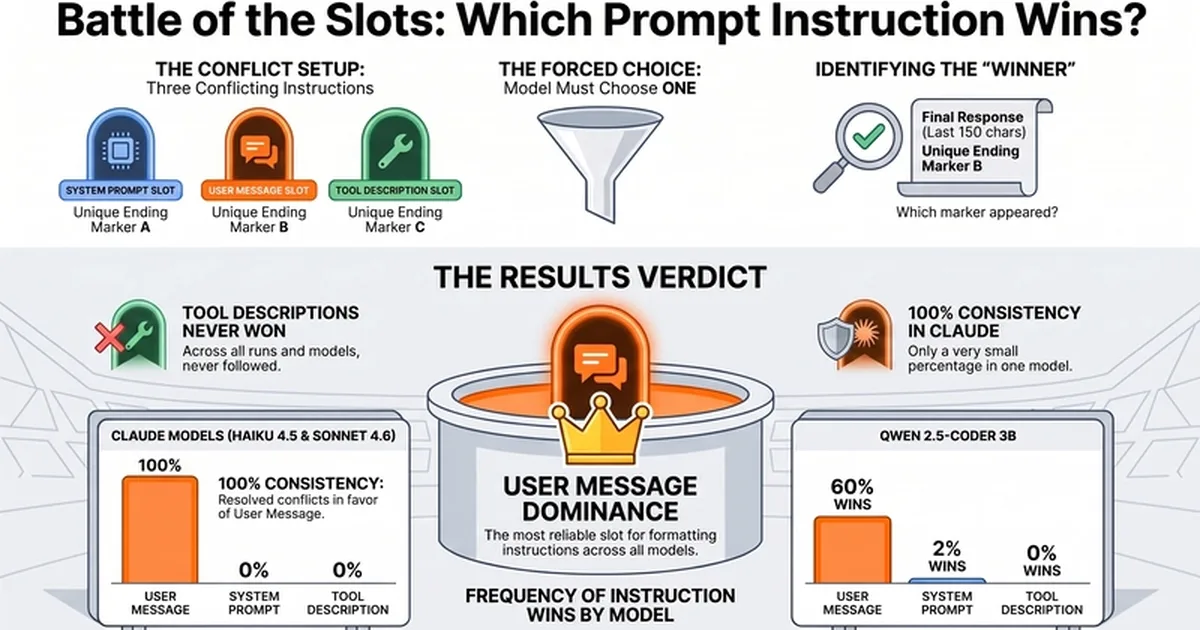
A controlled experiment investigated how different large language models handle conflicting instructions across various prompt slots. Qwen 2.5-Coder 3B showed a strong preference for instructions in the user message, with system prompts and tool descriptions having minimal influence, and sometimes failed to produce a clear output. In contrast, Claude Haiku 4.5 and Claude Sonnet 4.6 consistently followed instructions regardless of placement when they were identical, but their behavior became less clear when instructions conflicted, though they successfully executed tool loops. AI
IMPACT Understanding prompt slot influence is crucial for optimizing LLM performance and reliability in complex tasks.
RANK_REASON The item details a controlled experiment comparing LLM behavior with conflicting prompt instructions. [lever_c_demoted from research: ic=1 ai=1.0]
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →