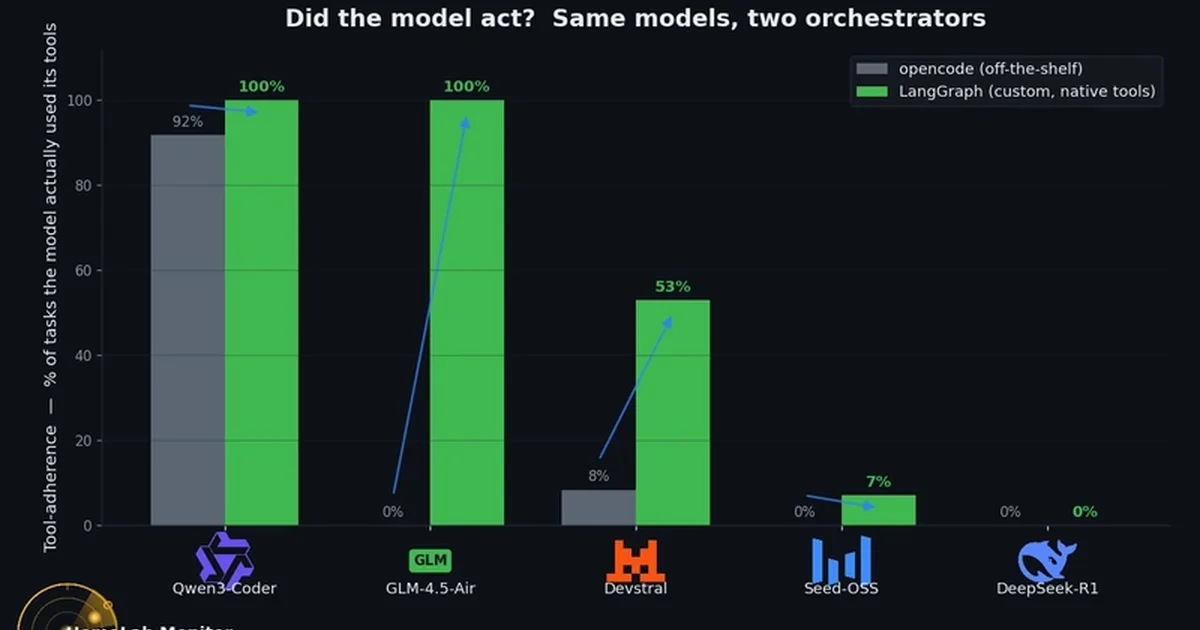
A benchmark study evaluated five local LLM models on an RTX 3090 GPU, focusing on their performance with different orchestration frameworks. The study found that the choice of framework, particularly one supporting native tool-calling like LangGraph, significantly impacts model effectiveness, with one model improving from a 0% success rate to 93% when using the appropriate agent. The research also highlighted the importance of tool adherence and measured the electricity cost per correct task, identifying Qwen3-Coder as an efficient and effective model for local agent tasks. AI
IMPACT Highlights the critical role of agent orchestration in unlocking LLM potential for local applications.
RANK_REASON Benchmark study comparing LLM models and orchestration frameworks.
AI-generated summary · Google Gemini · from 2 sources. How we write summaries →