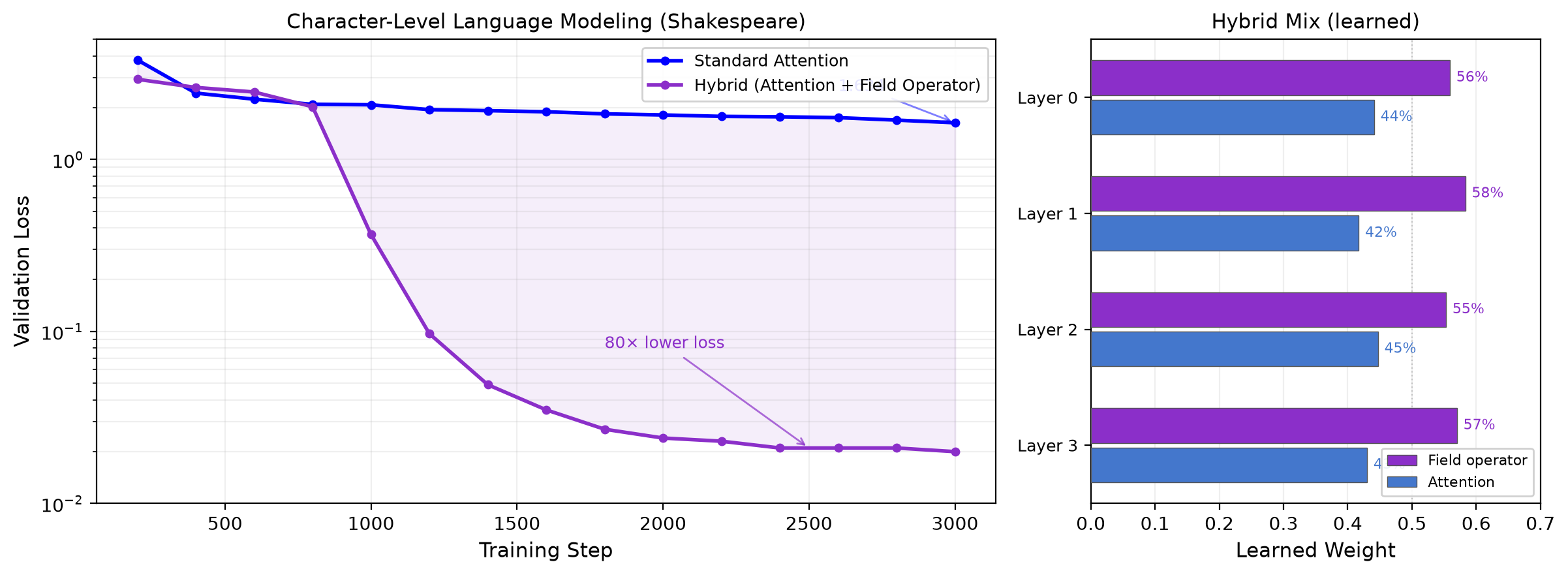
A novel operator called BeamGPT has been developed, which significantly improves learning curves in language models by identifying sequence structures that standard attention mechanisms miss. This operator, when integrated into a nanoGPT-style model, achieves a mix ratio of approximately 45% attention to 55% BeamGPT across layers. BeamGPT is linear in sequence length, offering a substantial advantage over the quadratic complexity of standard attention, leading to roughly 2.3 times savings at long contexts. Replacing standard MLP layers with BeamGPT resulted in a 73x lower training loss and a nearly 4x parameter reduction, though the exact notation of the operator is being withheld for careful release. AI
IMPACT Introduces a more efficient operator for language models, potentially reducing training costs and improving performance.
RANK_REASON Novel operator for language models described in a blog post, not a formal paper or release from a major lab. [lever_c_demoted from research: ic=1 ai=1.0]
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →