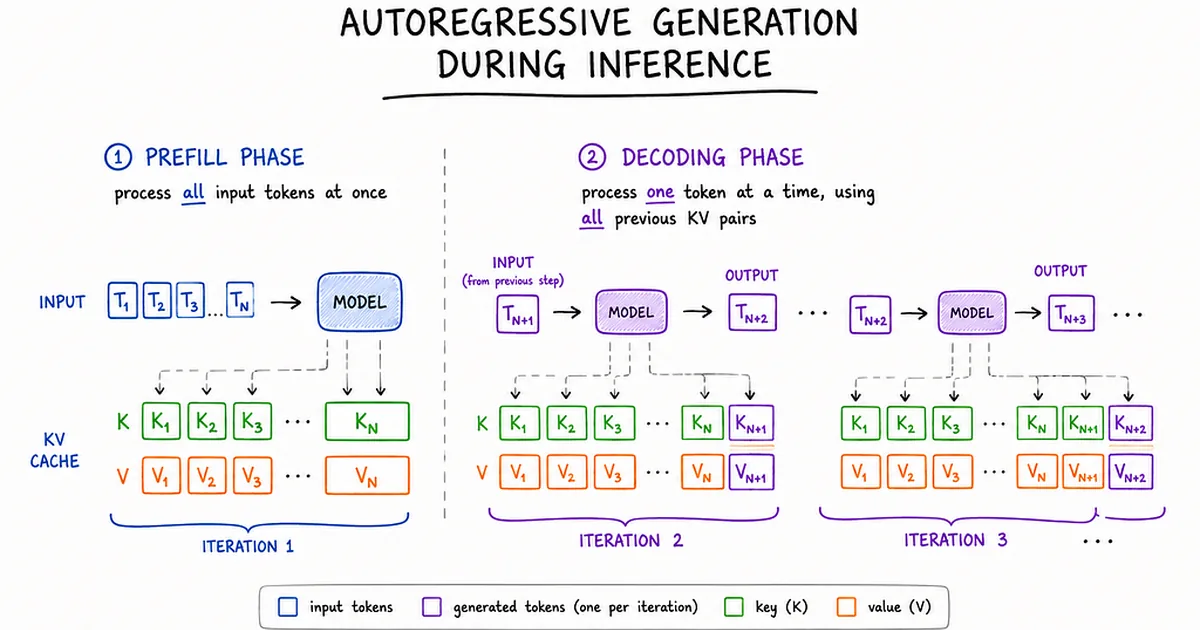
Modern large language model inference faces a systems challenge where the initial token generation (prefill) and subsequent token generation (decode) demand vastly different hardware behaviors. The prefill phase is compute-bound, processing all input tokens simultaneously, while the decode phase is memory-bound, requiring frequent loading of model weights from HBM for each token generated. This fundamental difference creates a conflict, as optimizing for one phase often compromises performance in the other, leading to a trade-off that impacts user experience through slow Time To First Token (TTFT) or sluggish Time Per Output Token (TPOT). AI
IMPACT Optimizing LLM inference for both prefill and decode phases is crucial for improving user experience and reducing computational costs.
RANK_REASON The item discusses a technical challenge in LLM inference related to hardware utilization and performance optimization, which falls under research. [lever_c_demoted from research: ic=1 ai=1.0]
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →