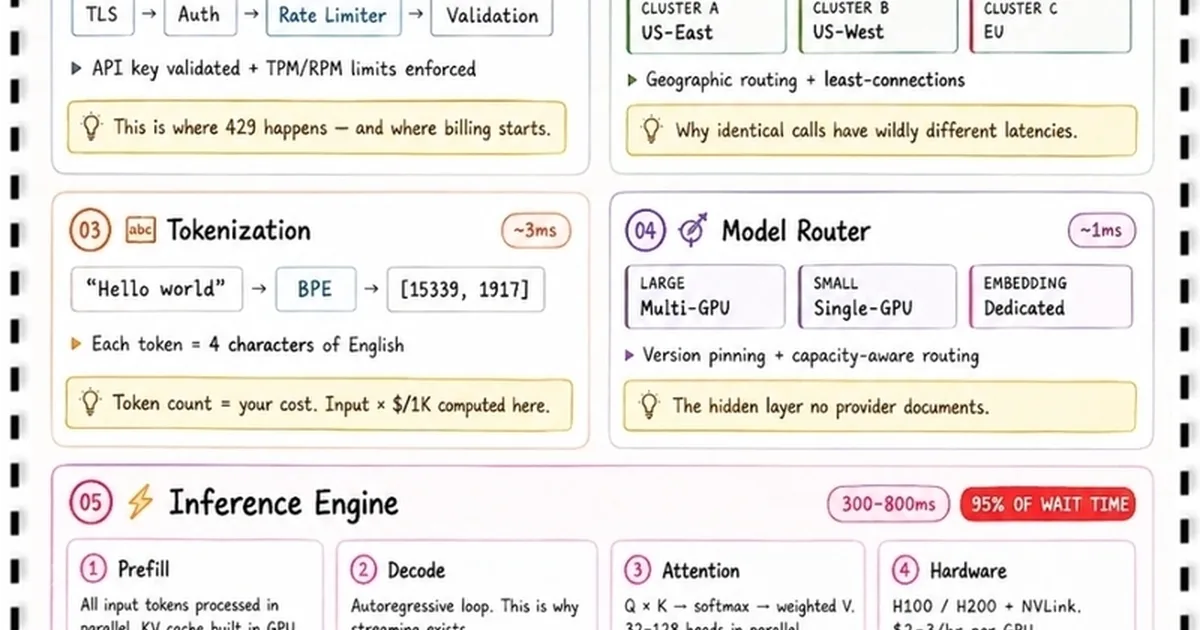
IntelliBooks AI has detailed the complex infrastructure behind Large Language Model (LLM) API calls, revealing a multi-layered process that goes beyond simple user interaction. The journey of a prompt involves an API Gateway for security and rate limiting, followed by a Load Balancer to distribute traffic efficiently across global resources. Subsequently, text is tokenized into numerical representations, and a Model Router selects the appropriate AI model and hardware for processing. Finally, the Inference Engine, often accelerated by GPUs like NVIDIA H100, performs the computationally intensive task of generating a response. AI
IMPACT Understanding LLM API infrastructure is crucial for optimizing AI application performance, cost, and scalability.
RANK_REASON The item explains the technical infrastructure behind LLM API calls, drawing on an infographic from IntelliBooks AI.
- API Gateway
- ChatGPT
- Claude
- Gemini
- Inference Engine
- IntelliBooks AI
- LLM
- Load Balancer
- Model Router
- NVIDIA H100
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →