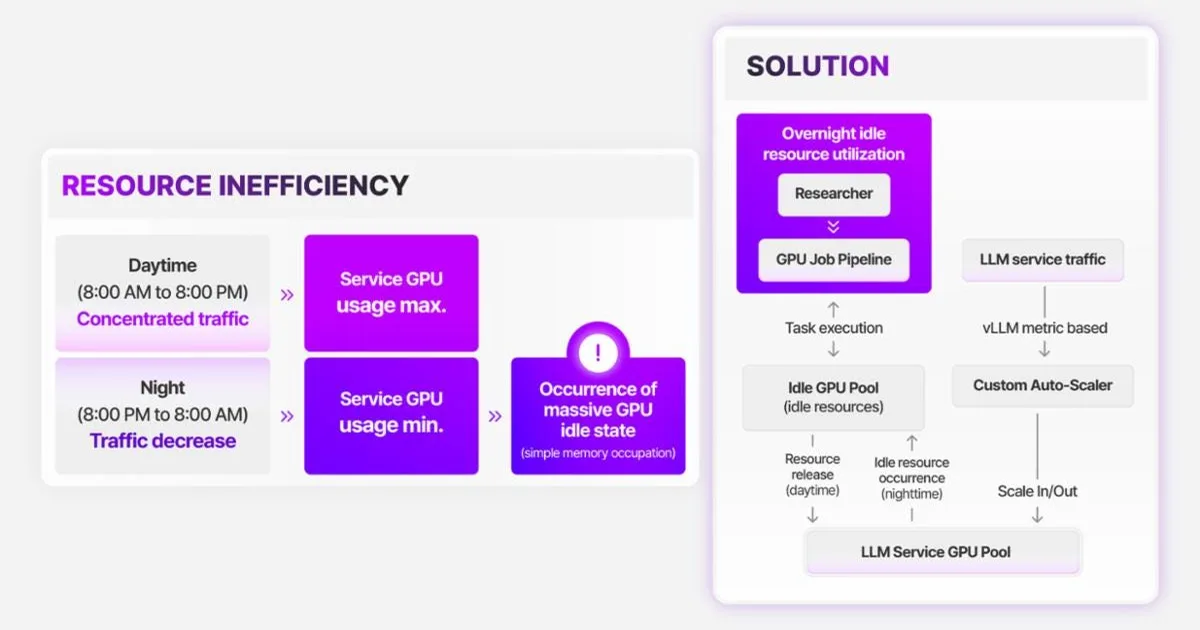
This article explores the economics and practicality of running AI inference tasks on local GPUs versus cloud-based solutions. It argues that for certain workloads, particularly those with fluctuating or low demand, local GPU inference can become more cost-effective than cloud services due to the absence of marginal costs per token. The discussion also touches upon efficient GPU job scheduling and resource management within an MLOps framework to optimize the utilization of these local resources. AI
IMPACT Local GPU inference may offer cost savings for certain AI workloads, influencing infrastructure decisions for AI operators.
RANK_REASON The cluster discusses the economic and operational aspects of using local GPUs for AI inference, comparing it to cloud services, which falls under commentary on AI infrastructure and MLOps practices.
AI-generated summary · Google Gemini · from 2 sources. How we write summaries →