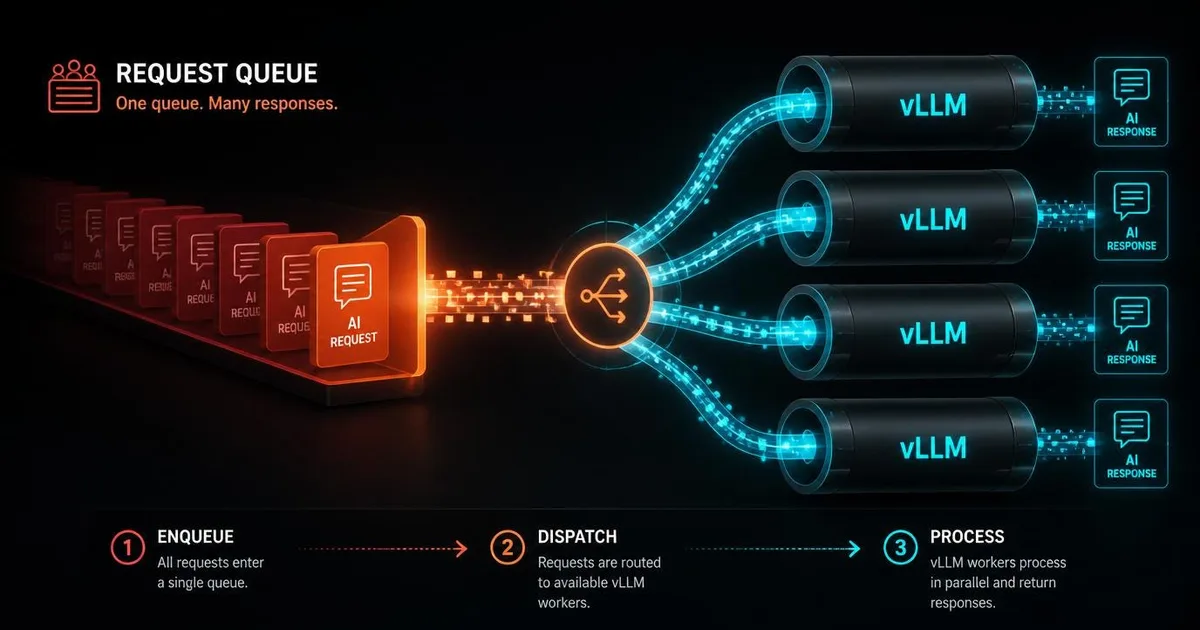
This article details how to optimize the vLLM inference engine for AMD hardware, specifically on a Lemonade Server. The author shares their experience fixing issues and achieving a threefold increase in batch throughput when using the Qwen3.5 model. The guide aims to help users overcome common problems and improve performance on their AMD-based systems. AI
IMPACT Optimizing inference engines like vLLM on diverse hardware can accelerate AI deployment and reduce operational costs.
RANK_REASON The article describes a technical optimization for a specific software and hardware combination, which falls under tooling.
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →