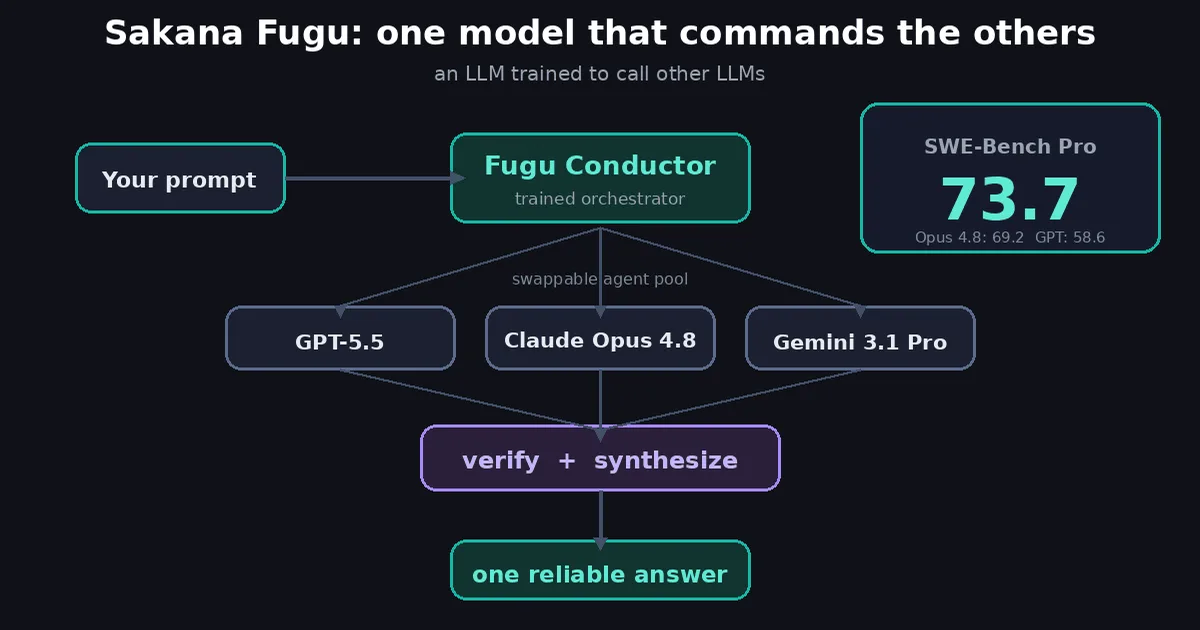
Sakana, a Tokyo-based lab, has developed an AI model capable of commanding GPT-5.5, achieving a score of 73.7 on the SWE-Bench Pro benchmark. This performance surpasses that of Anthropic's Claude Opus 4.8, which scored 69.2, and OpenAI's GPT-5.5, which achieved 58.6 on the same test. The development highlights advancements in AI agent capabilities and benchmark performance. AI
IMPACT This development sets a new benchmark for AI agent performance in coding tasks, potentially influencing future model development and evaluation.
RANK_REASON The item reports on a new benchmark score for an AI model, which is a research milestone. [lever_c_demoted from research: ic=1 ai=1.0]
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →