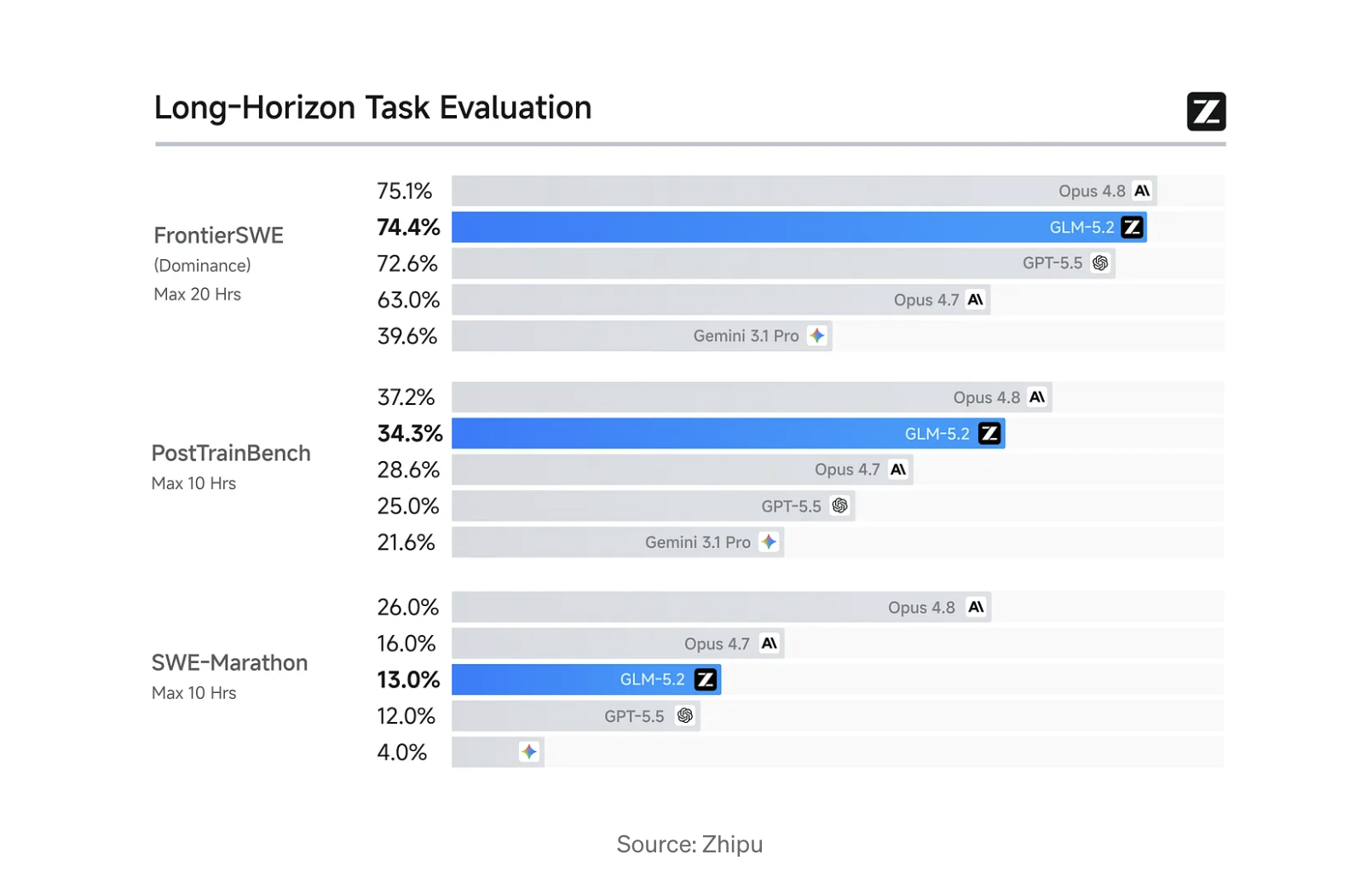
Zhipu AI's GLM-5.2, a Chinese frontier model, has reportedly achieved strong performance on coding benchmarks, surpassing OpenAI's GPT-5.5 and Anthropic's Claude Opus 4.7. On the FrontierSWE benchmark, GLM-5.2 scored 74.4%, narrowly trailing Claude Opus 4.8 but outperforming GPT-5.5. The model also demonstrated significant gains on Terminal-Bench 2.1 and matches the coding capabilities of leading proprietary models, while being available as an open-source option. AI
IMPACT Sets new SOTA on coding benchmarks, challenging leading proprietary models and potentially accelerating the adoption of open-source alternatives.
RANK_REASON Frontier-lab model release with benchmark results. [lever_c_demoted from frontier_release: ic=1 ai=1.0]
Read on Mastodon — fosstodon.org →
- China
- Claude Opus 4.7
- Claude Opus 4.8
- FrontierSWE
- GLM-5.2
- GPT-5.5
- SWE-bench Pro
- Terminal-Bench 2.1
- Zhipu AI
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →