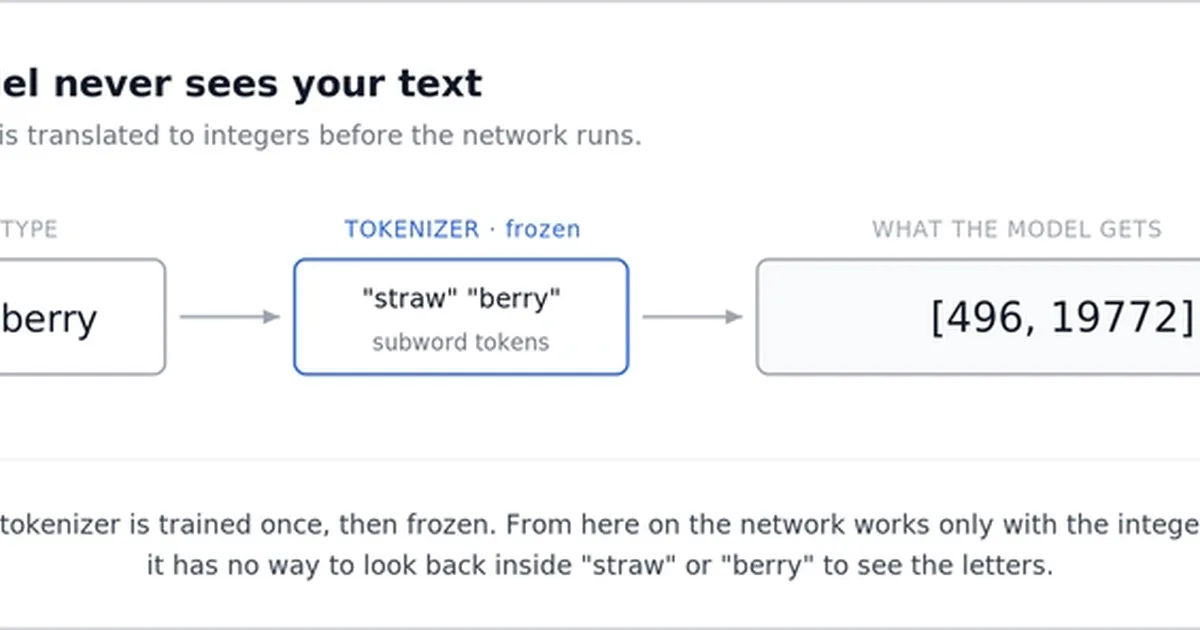
Large language models struggle with tasks like counting letters or rhyming because their input is processed by a tokenizer, typically using Byte Pair Encoding (BPE), which converts text into integer token IDs. This process destroys character-level information, meaning the model operates on opaque sequences rather than raw text. While BPE merges frequent character pairs into tokens, it prioritizes frequency over linguistic structure, leading to common words becoming single tokens and rare words being fragmented. Consequently, tasks requiring character-level analysis, such as counting letters or spelling backwards, are difficult for LLMs as they lack direct access to this information and must rely on pattern matching from training data. AI
IMPACT Understanding LLM tokenization limitations is crucial for developers to anticipate model behavior and design prompts effectively for tasks requiring character-level manipulation.
RANK_REASON The item explains a technical limitation of LLMs related to their tokenization process, offering an analysis rather than announcing a new release or research.
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →