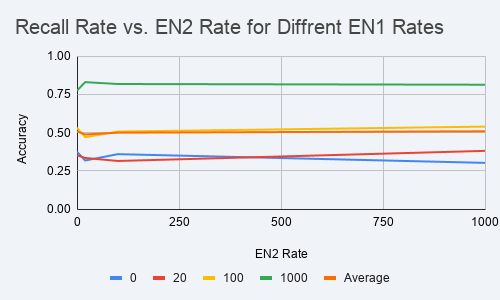
Researchers have found that large language models struggle to generalize even when presented with two identical copies of the same language. This challenges common assumptions that issues in multilingual performance stem from syntax, tokenizer fragmentation, or data imbalance. An experiment involving pretraining was conducted to investigate this phenomenon further. AI
Summary written by gemini-2.5-flash-lite from 1 source. How we write summaries →
IMPACT Highlights potential limitations in LLM generalization, suggesting current architectures may not effectively handle even simple linguistic variations.
RANK_REASON The cluster describes a research finding about LLM generalization capabilities.