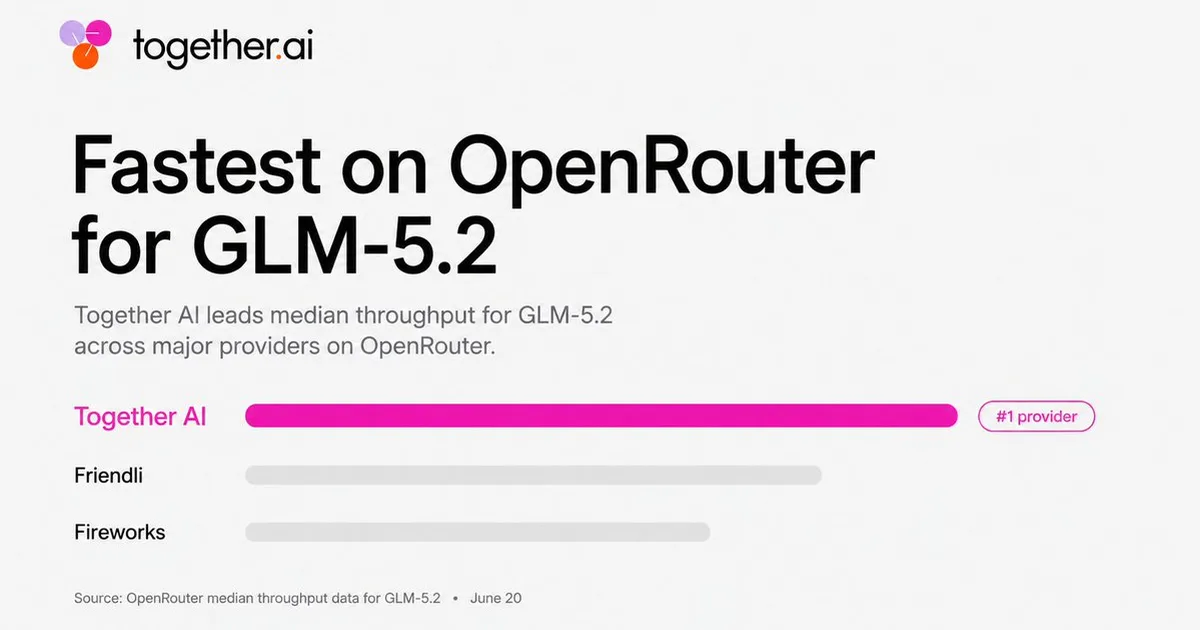
Together AI is now offering GLM-5.2, a model that is reportedly fast and capable of handling long-context coding and agent workloads. The company emphasizes its optimized serving infrastructure, which allows for high throughput (TPS) on platforms like OpenRouter. This development highlights Together AI's focus on efficient inference for demanding AI tasks. AI
IMPACT Accelerates availability of efficient inference for LLMs, potentially lowering costs for AI developers.
RANK_REASON This is a tool/infra announcement from a company that is not a frontier model lab, about a model that is not explicitly stated as new.
Read on X — Together (inference / OSS) →
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →