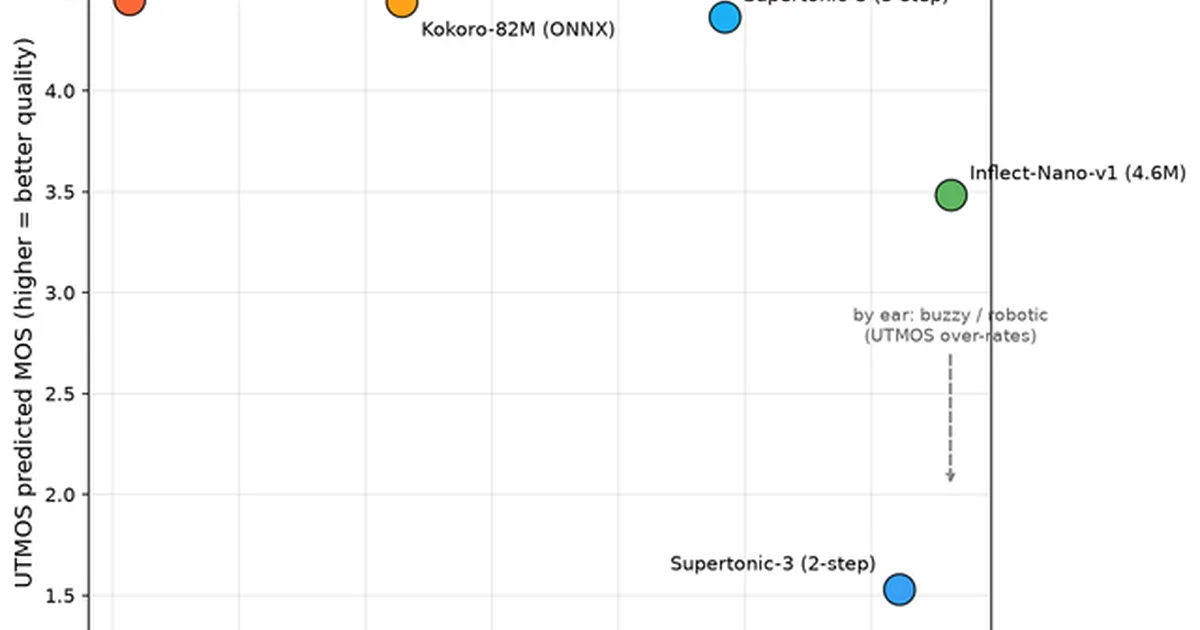
A benchmark comparing three open-weight Text-to-Speech (TTS) models—Kokoro 82M, Supertonic 3, and Inflect-Nano-v1—on a CPU revealed significant performance and quality differences. Inflect-Nano-v1, despite its small parameter count and fastest real-time factor (RTF) of 0.1376, was found to be over-rated by UTMOS scoring and suffers from a hard output length limitation. Supertonic 3 offered a trade-off, with a 5-step configuration achieving a MOS of 4.37 at an RTF of 0.3164, while Kokoro 82M, though the slowest with RTFs between 0.5711 and 0.7865, produced the most human-like audio. AI
IMPACT Provides insights into the trade-offs between speed and audio quality for CPU-based TTS models, guiding developers on model selection.
RANK_REASON The cluster details a benchmark comparing multiple open-weight TTS models, including performance metrics and quality assessments. [lever_c_demoted from research: ic=1 ai=1.0]
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →