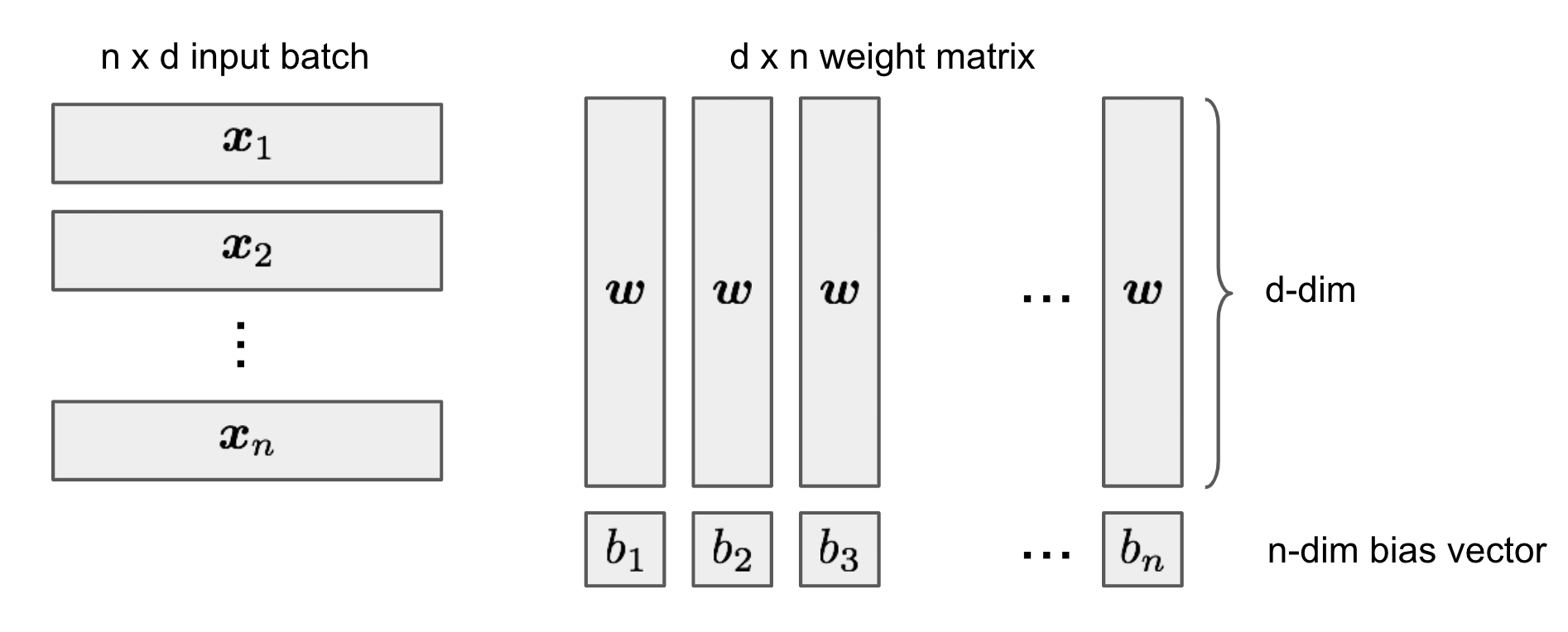
This post delves into the question of why deep neural networks, despite their numerous parameters, can generalize well to new data. It explores classic principles like Occam's Razor and the Minimum Description Length (MDL) principle, which suggest that simpler models are more likely to be correct and that learning can be viewed as data compression. The MDL principle, in particular, formalizes the idea that a good model should not only explain the data but also be concise, thereby aiding generalization. AI
Summary written by gemini-2.5-flash-lite from 1 source. How we write summaries →
RANK_REASON This is a blog post discussing theoretical concepts and classic papers related to machine learning generalization.