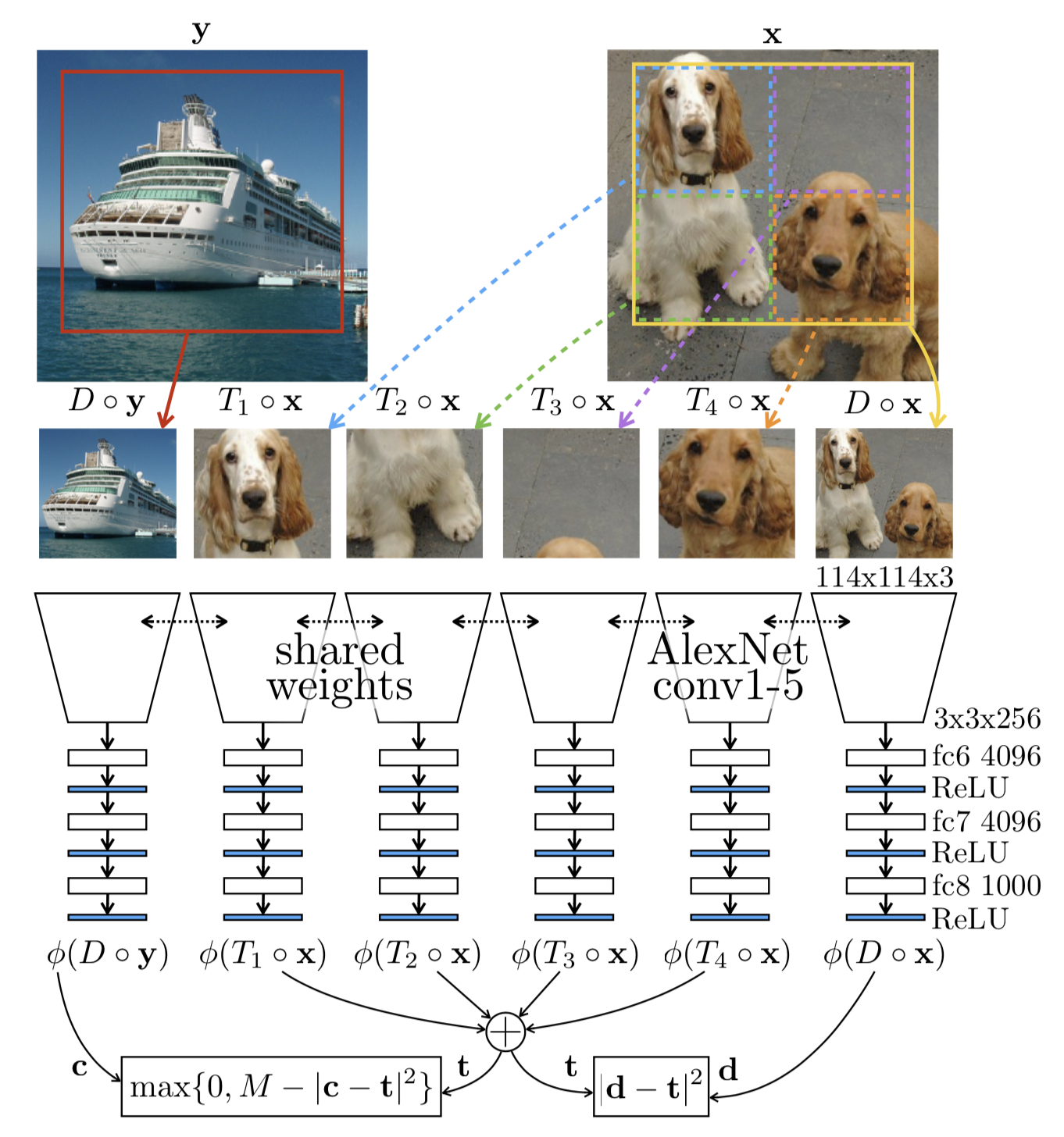
This post explores self-supervised learning, a method that leverages readily available unlabeled data by creating supervised tasks from the data itself. The core idea is to train models on these 'pretext' tasks, not for their own sake, but to learn intermediate representations that are useful for various downstream applications. This approach addresses the high cost and limited scalability of manual data labeling, enabling the exploitation of vast amounts of unlabeled text and images. The post highlights its application in language modeling and discusses image-based self-supervised learning techniques. AI
Summary written by gemini-2.5-flash-lite from 1 source. How we write summaries →
RANK_REASON The item is a blog post summarizing research papers on self-supervised learning.