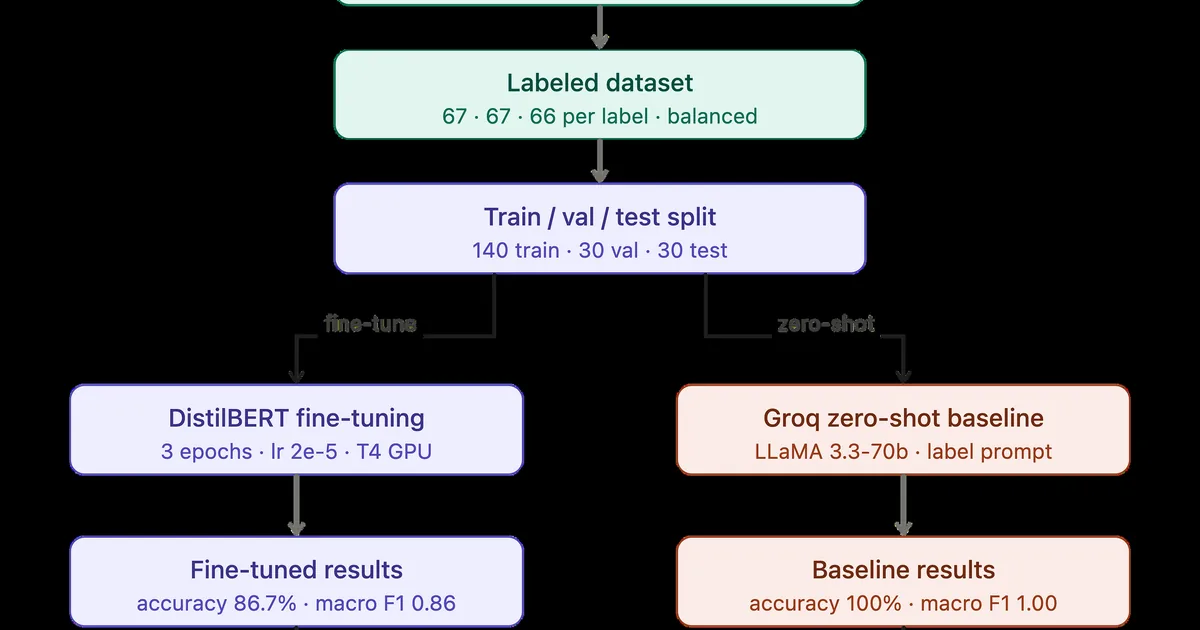
Fine-tuning large language models offers a more efficient alternative to training from scratch, allowing users to adapt pre-existing models to specific tasks. However, the most challenging aspect of fine-tuning is not the computational training process itself, but rather the meticulous work involved in data labeling and identifying model failures. This highlights the critical role of data quality and error analysis in achieving successful fine-tuning outcomes. AI
IMPACT Highlights that effective fine-tuning relies more on data preparation and error analysis than on the training process itself.
RANK_REASON The cluster consists of two opinion pieces discussing the nuances of fine-tuning LLMs, rather than a primary release or significant industry event.
Read on Medium — fine-tuning tag →
AI-generated summary · Google Gemini · from 2 sources. How we write summaries →