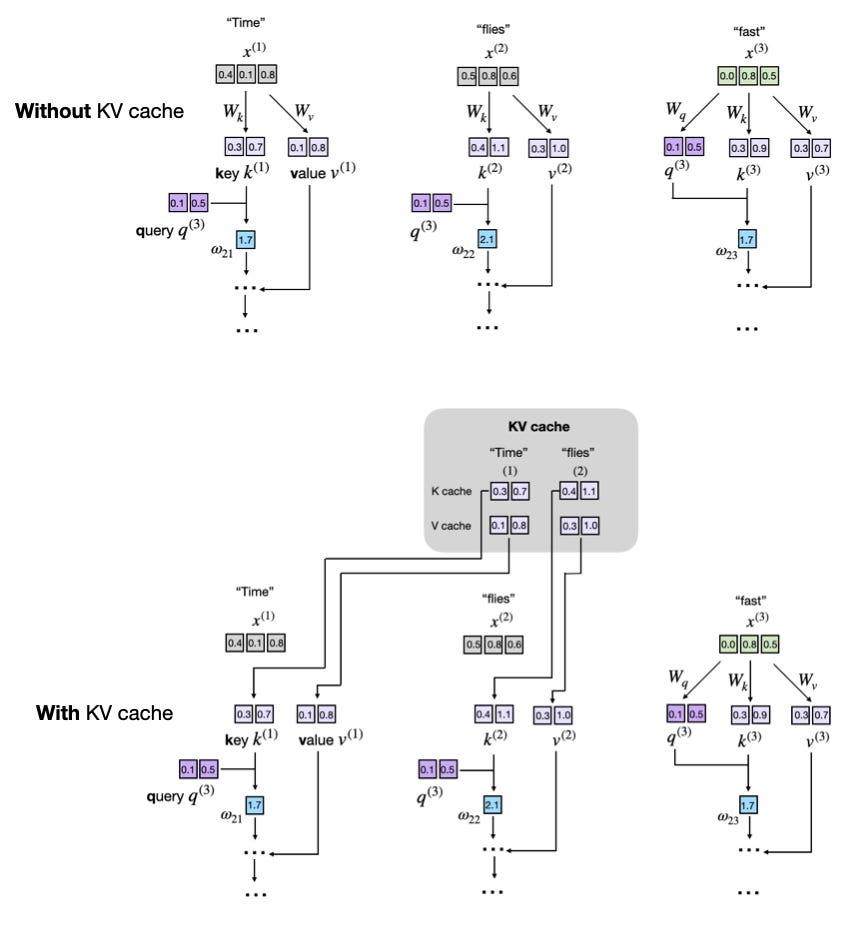
The KV cache is a crucial technique for optimizing the inference speed of Large Language Models (LLMs) in production environments. It works by storing and reusing intermediate key and value computations, thereby avoiding redundant calculations during text generation. While it increases memory requirements and code complexity, the significant inference speed-ups often make it a worthwhile trade-off for deploying LLMs. AI
RANK_REASON This is a technical tutorial explaining a fundamental LLM concept with a code implementation.
Read on Ahead of AI (Sebastian Raschka) →
AI-generated summary · Google Gemini · from 2 sources. How we write summaries →