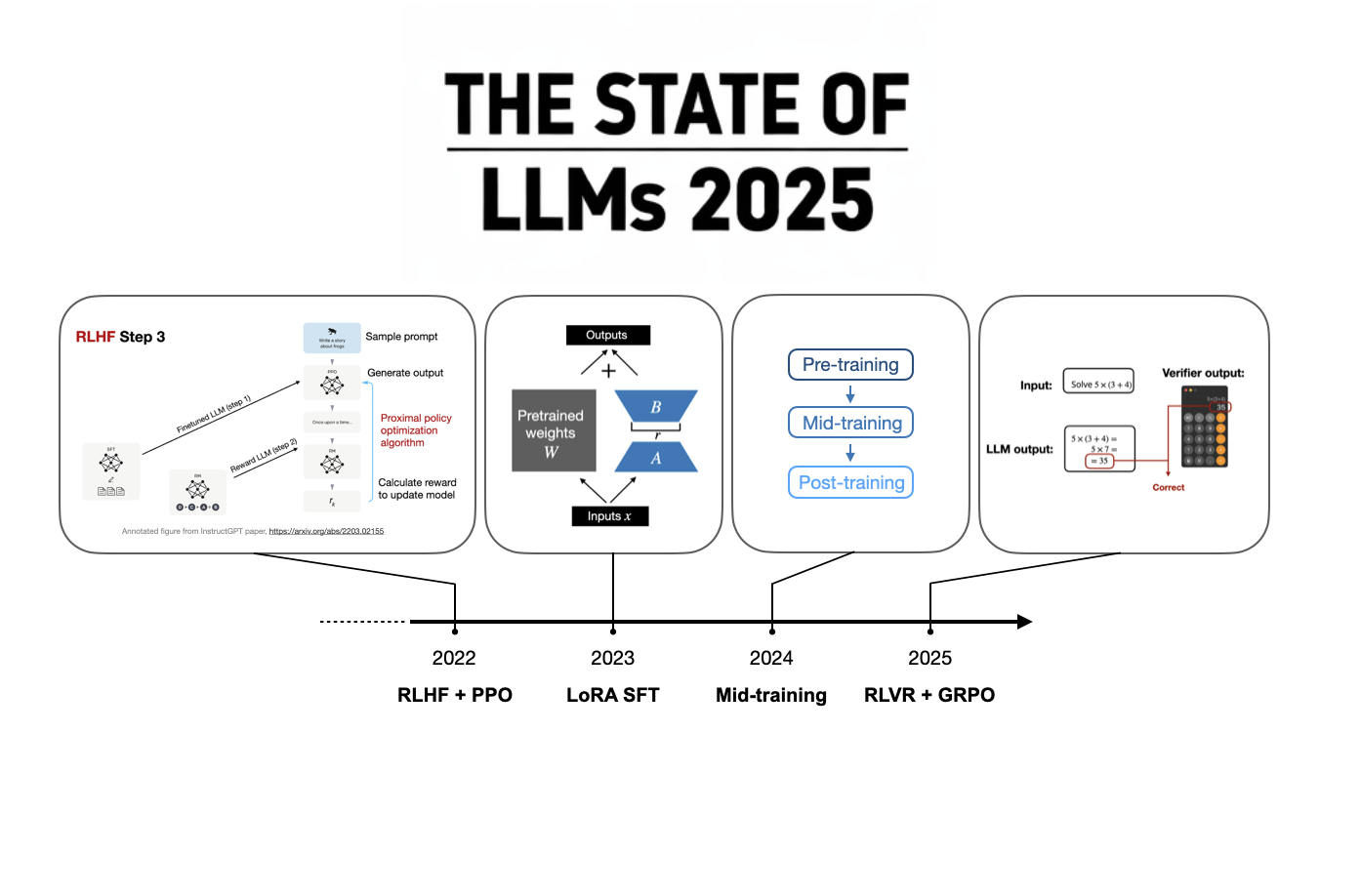
The year 2025 was marked by significant advancements in large language models, particularly in the development of reasoning capabilities. A key breakthrough was DeepSeek's R1 model, which demonstrated that reasoning skills could be effectively trained using reinforcement learning with verifiable rewards (RLVR) and the GRPO algorithm. This approach proved to be more cost-effective than previously thought, with training costs estimated around $5 million. The success of DeepSeek R1 spurred other major LLM developers, both open-weight and proprietary, to release their own reasoning-enhanced models, shifting the focus of LLM development. AI
Summary written by None from 9 sources. How we write summaries →
RANK_REASON The cluster focuses on research papers and technical reports detailing advancements in LLM reasoning capabilities, including new training methods and model releases from various labs.