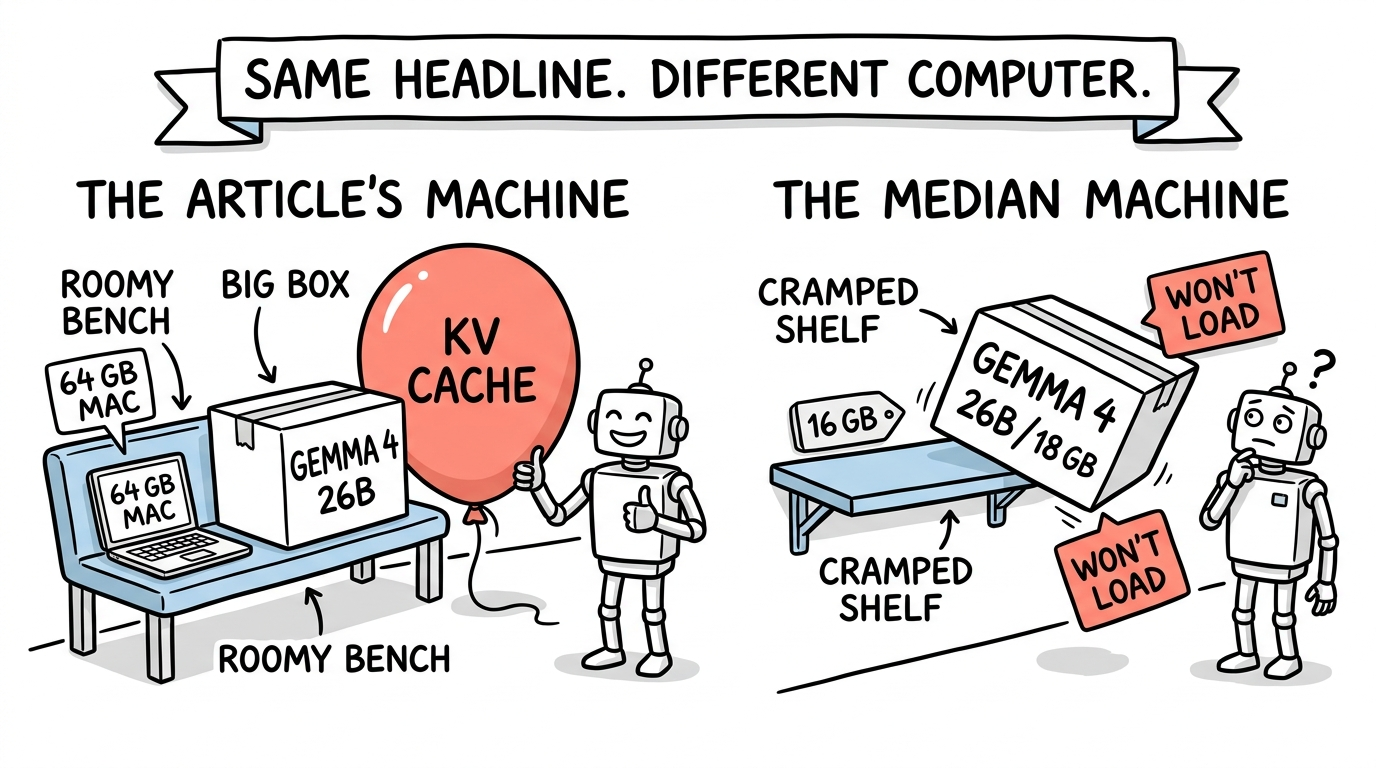
Running large language models locally on consumer hardware is becoming more feasible, though system specifications remain a significant factor. A 64GB Mac was used to demonstrate current capabilities, highlighting that over half of personal computers have 16GB of RAM or less. The article details which local LLMs can fit within these constraints, the memory costs associated with KV cache, and the performance differences between Mac and PC hardware with similar RAM. AI
IMPACT Highlights the growing accessibility of local LLMs for users with standard consumer hardware, despite RAM limitations.
RANK_REASON Article discusses the feasibility of running LLMs on consumer hardware, focusing on RAM limitations, rather than announcing a new model or research.
AI-generated summary · Google Gemini · from 1 sources. How we write summaries →