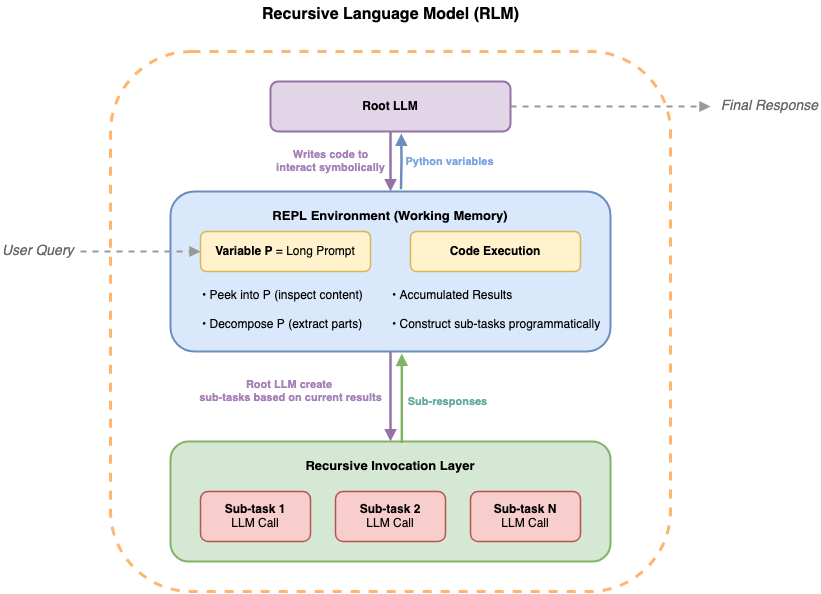
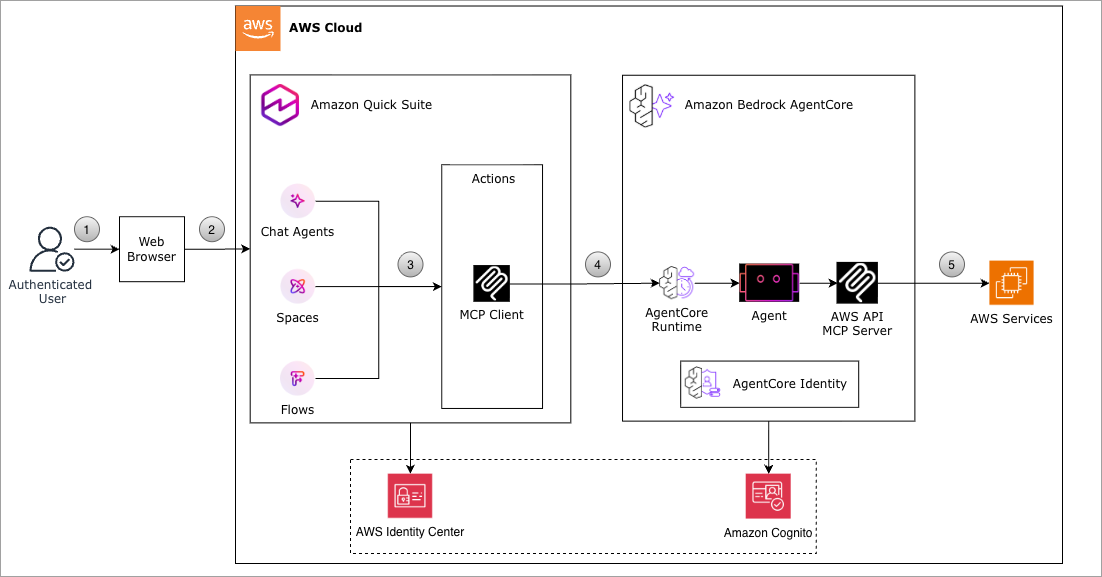
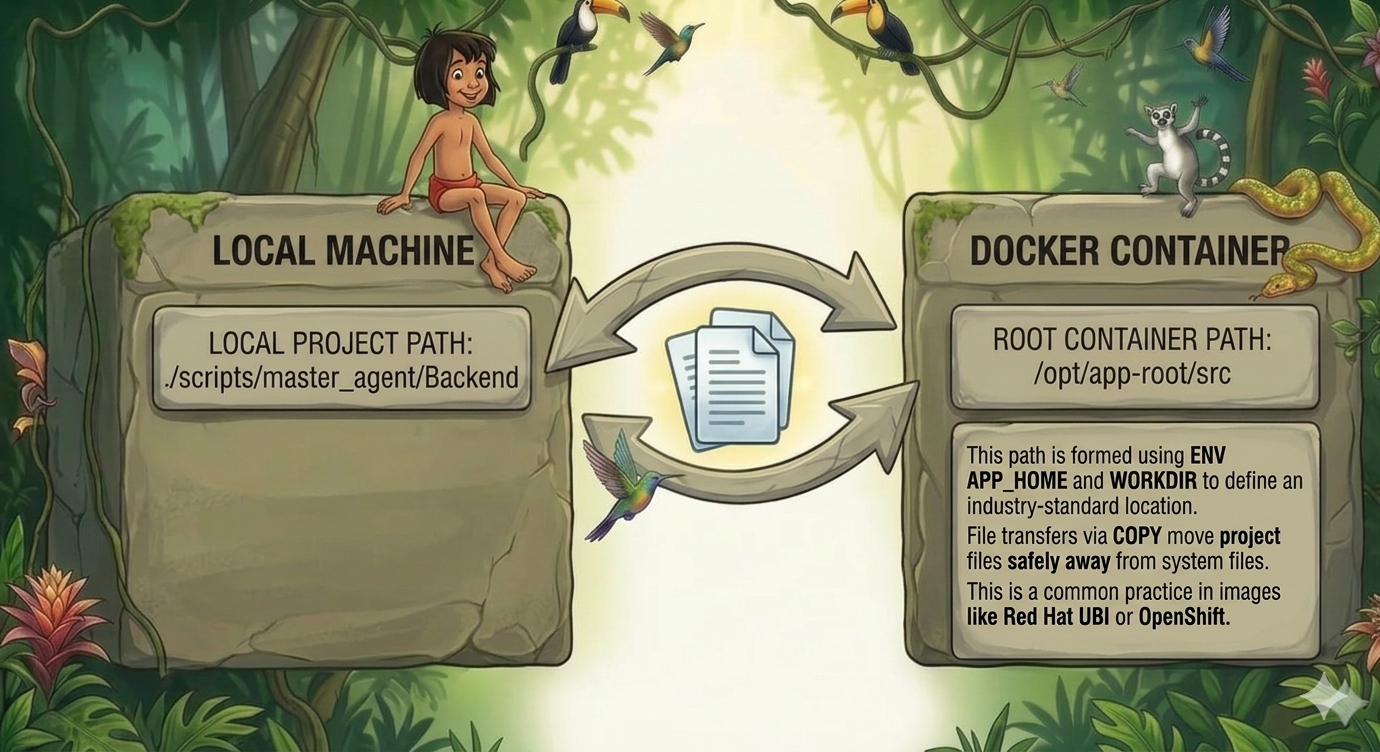
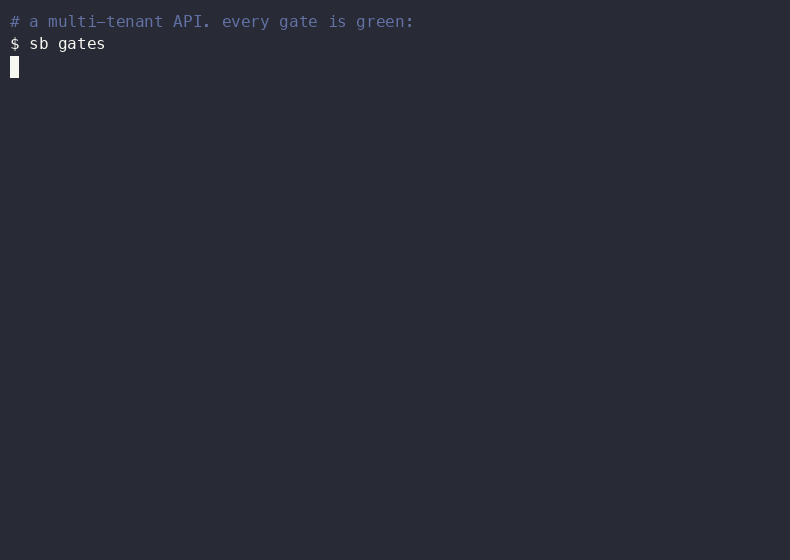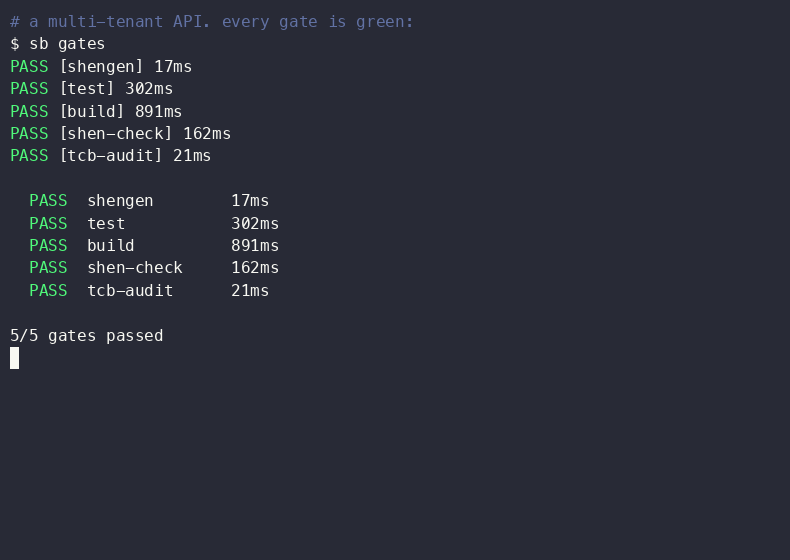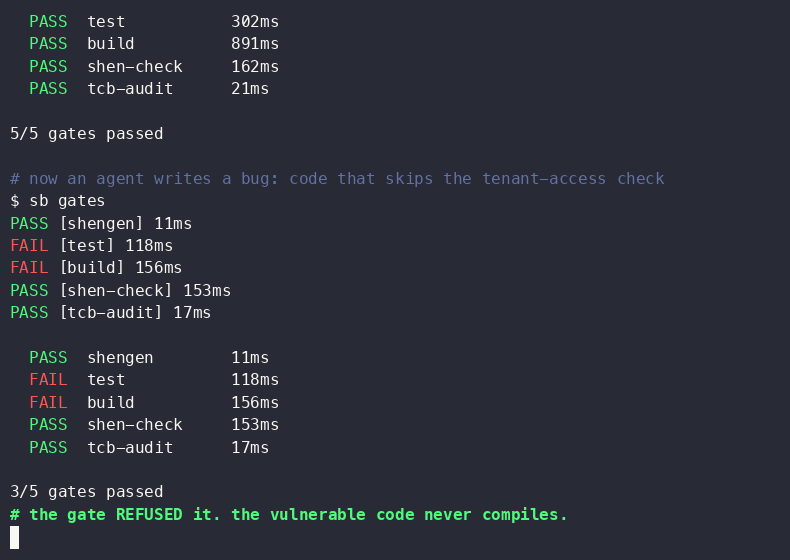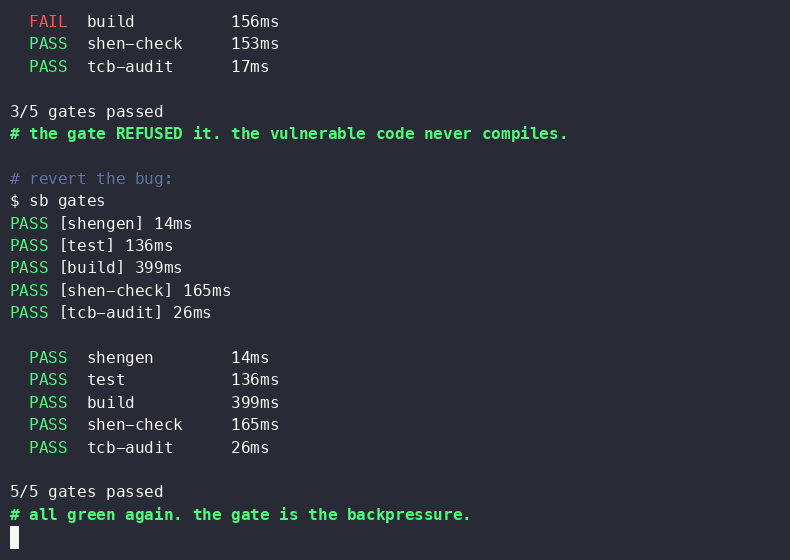
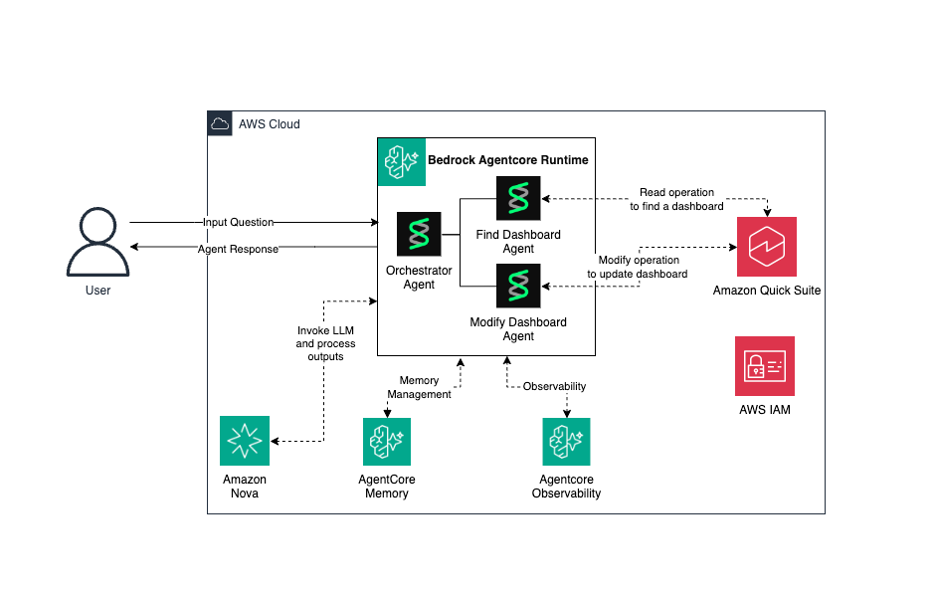
Three token-saving patterns stacked doubled token usage. Caching held the line.
The author explored methods to optimize token usage in large language models, specifically within the Databricks environment. They found that while combining three token-saving patterns initially doubled token consumption, implementing caching strategies effectively mitigated this increase. The experiments focused on practical application and efficiency within a specific platform. AI
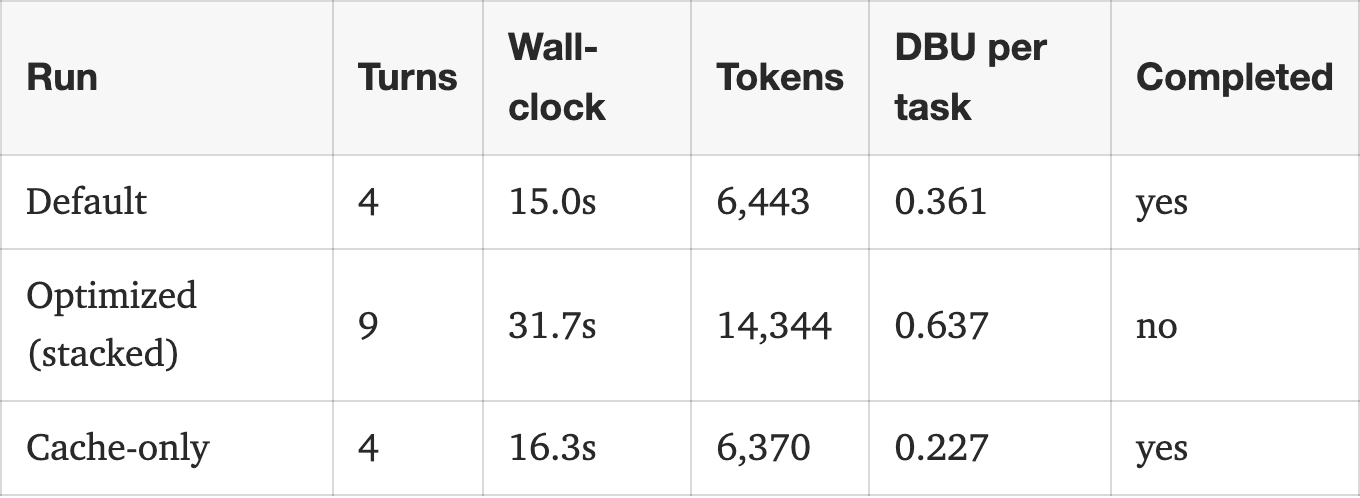
IMPACT Demonstrates practical techniques for reducing operational costs in LLM deployments.