Real-Time Earthquake Magnitude Classification from Initial P-Waves: Models, Dataset, and Comparative Analysis for South Asia
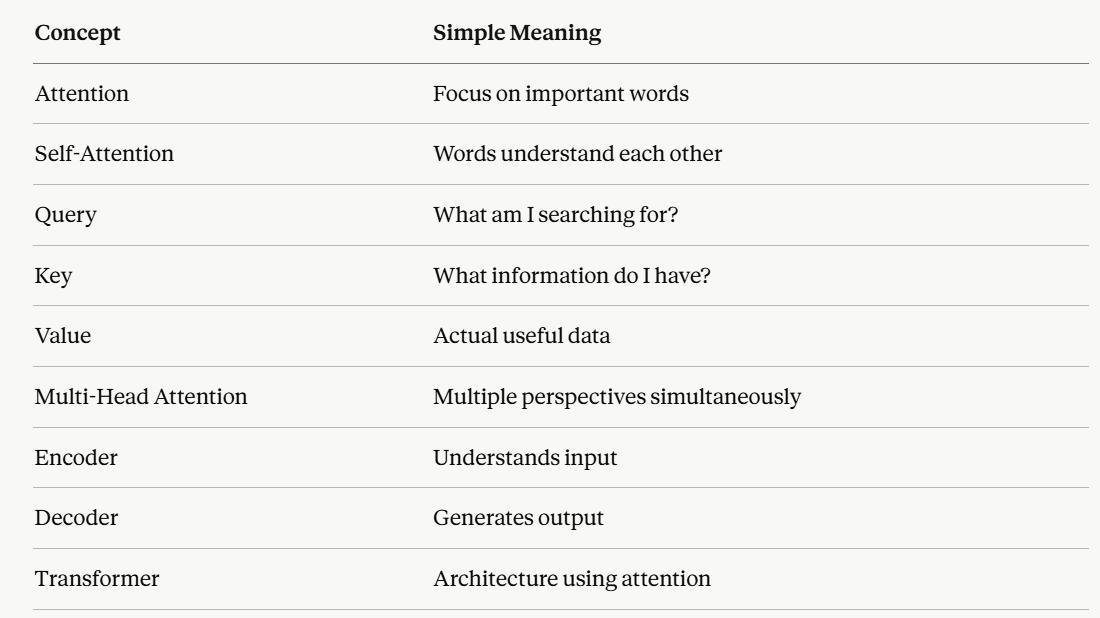
Researchers have developed a new method for classifying earthquake magnitudes in real-time using initial P-wave data. Their study compares six machine learning approaches, finding that Transformer-based deep learning models significantly outperform traditional methods. The proposed Transformer architecture achieved 76.23% standard accuracy and 81.56% adaptive accuracy with a low inference latency, making it suitable for real-time deployment. AI
IMPACT Enables faster and more accurate earthquake early warnings, potentially saving lives and reducing damage.