SVM : 40 Must Visit Interview Questions (Part 1)
This article series delves into Support Vector Machines (SVMs), a popular machine learning algorithm, by presenting a comprehensive list of interview-style questions. Part 1 covers foundational concepts like decision boundaries, hyperplanes, and the intuition behind maximizing margins, along with distinctions between hard-margin and soft-margin classifiers. Part 2 builds on this by exploring the kernel trick, its power, different kernel types, and challenges, as well as how SVMs handle multi-class problems and compare to other algorithms like Logistic Regression. AI
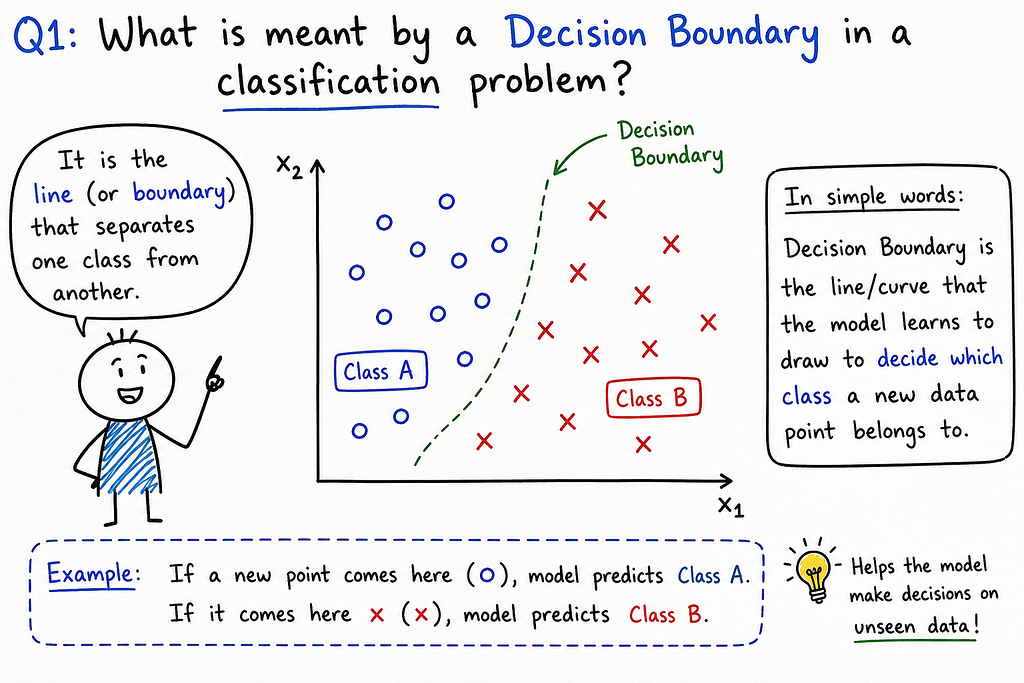
IMPACT Provides foundational knowledge for machine learning practitioners and students preparing for interviews on core algorithms.

