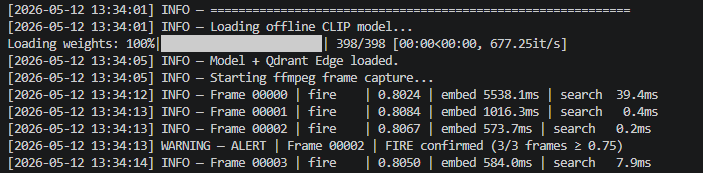
Cost accounting for diffusion image generation at $0.0008 per render
Photoroom significantly reduced its image generation costs by optimizing its diffusion pipeline. The company achieved a 39% cost reduction on the UNet denoising stage through int8 quantization and a 79% reduction in text-encoder costs by caching LLM embeddings. Implementing an AI gateway with Bifrost further decreased caption API spend by 61% and improved latency, while also mitigating costs associated with upstream LLM outages. AI
IMPACT Demonstrates significant cost-saving strategies for AI-driven image generation services, potentially lowering operational expenses for similar products.