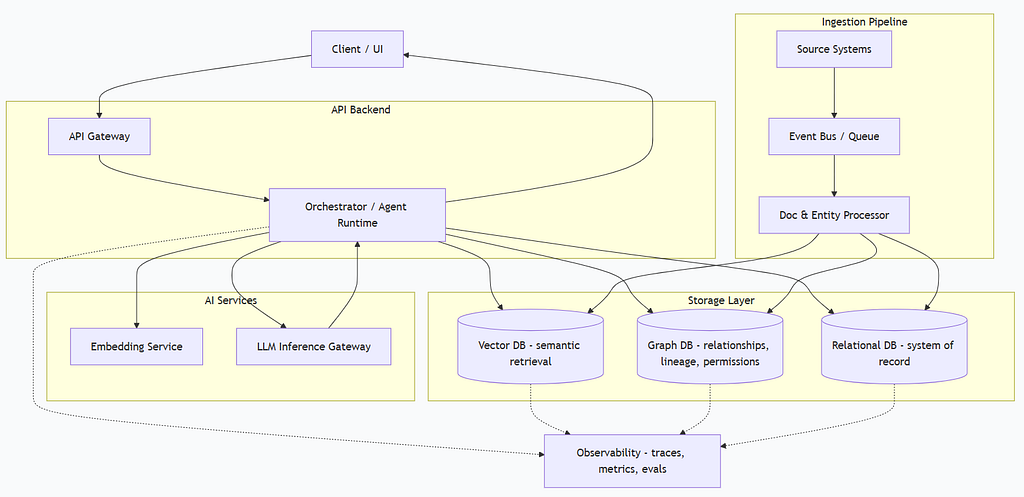
Your agent's memory should compute confidence, not store it
A new approach to AI agent memory proposes computing confidence dynamically rather than storing it statically. This method, termed Recall, recalculates a claim's confidence based on its relationships within a graph database, factoring in corroboration and contradiction. Unlike traditional methods that store a fixed confidence score, Recall's formula adjusts a claim's value based on its support and challenge edges, as well as the author's track record, ensuring that new information or contradictions immediately impact the perceived reliability of a memory. AI

IMPACT This approach could lead to more robust and adaptable AI agents by ensuring their knowledge base dynamically reflects new information and contradictions.