We're open-sourcing the Unigram tokenizer we rebuilt to reduce CPU utilization by 5-6x.
Perplexity AI has open-sourced a new Unigram tokenizer designed to significantly improve CPU performance. This new tokenizer achieves a 5x reduction in latency compared to HuggingFace's implementation and a 2x reduction compared to SentencePiece C++. The optimized tokenizer targets large vocabularies, such as XLM-RoBERTa's 250K-token Unigram vocabulary, which is commonly used in ranking and retrieval tasks. AI
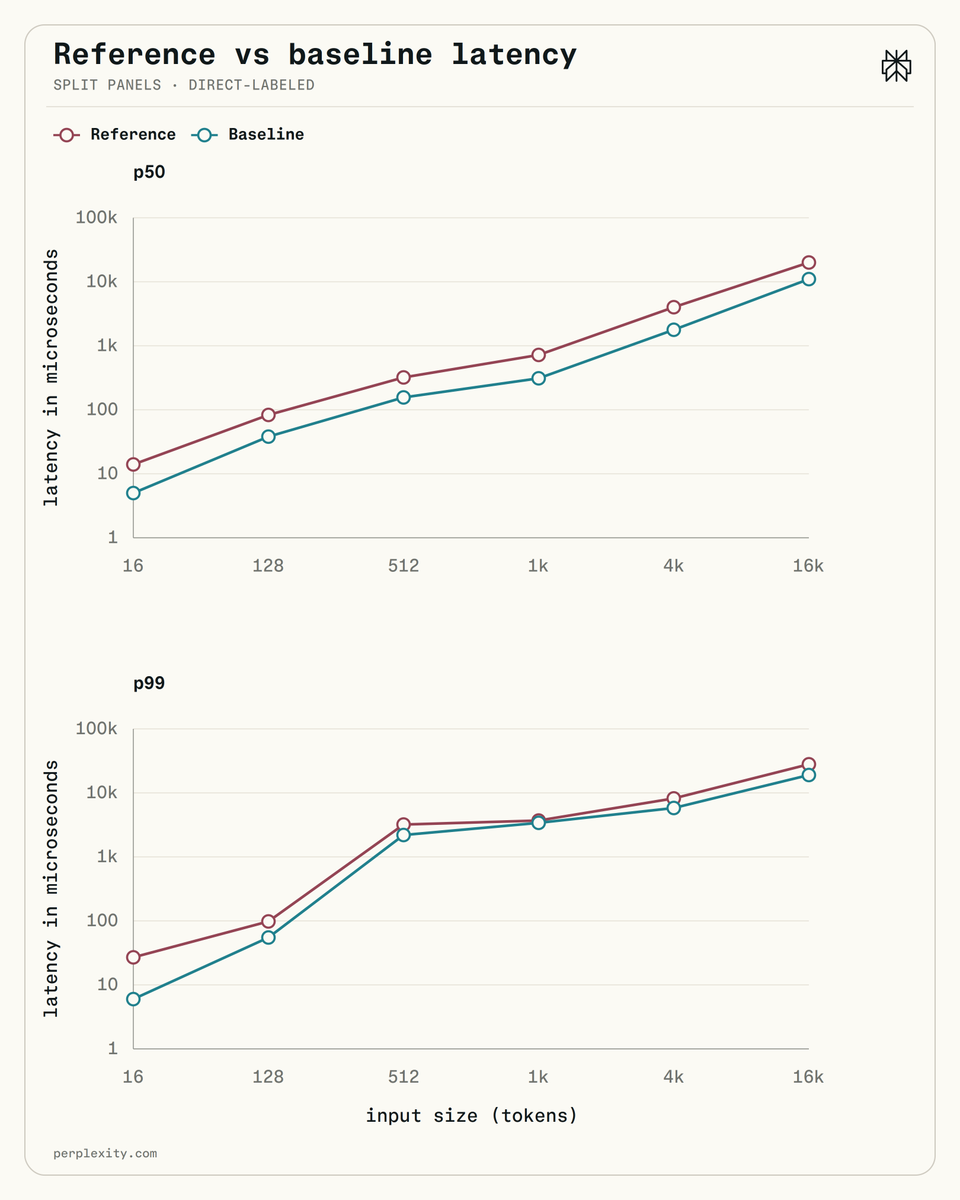
IMPACT Accelerates inference for AI models by reducing tokenization latency on CPUs.