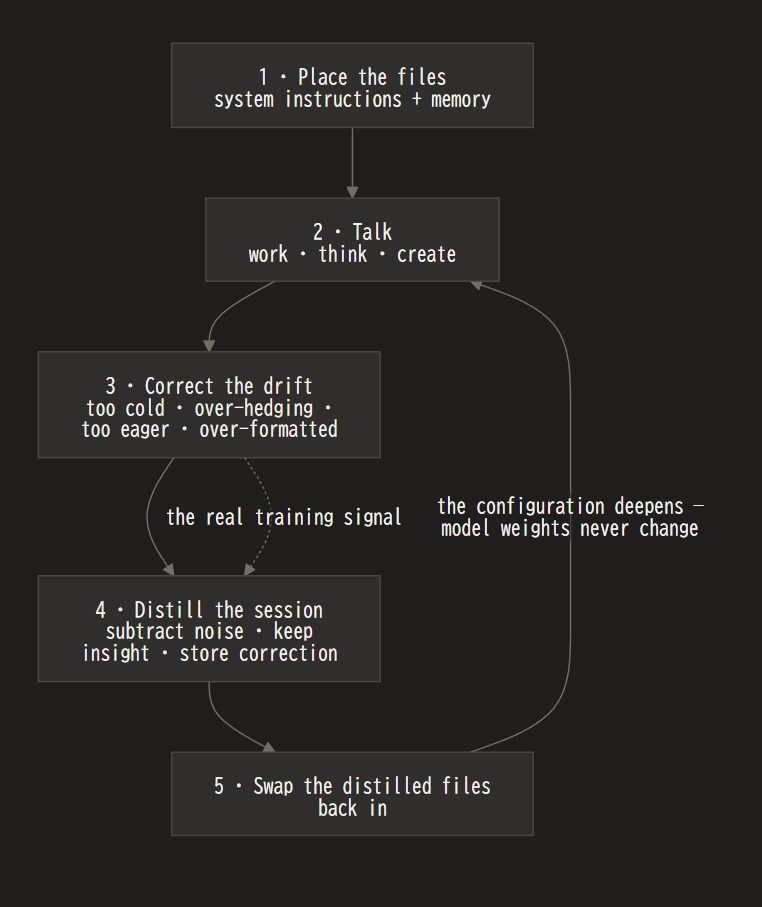
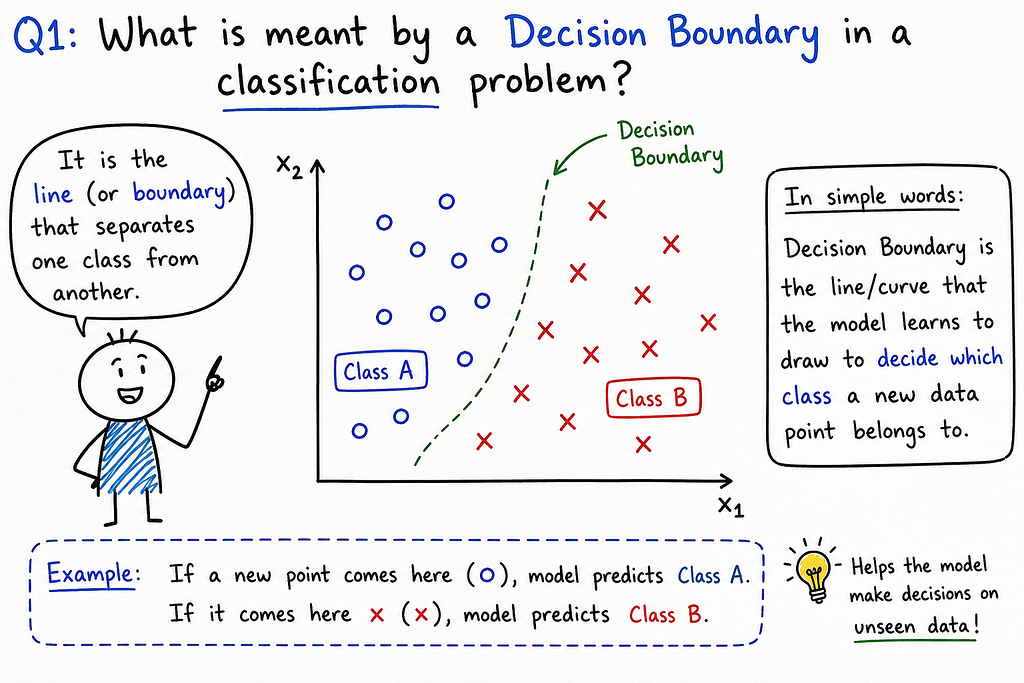
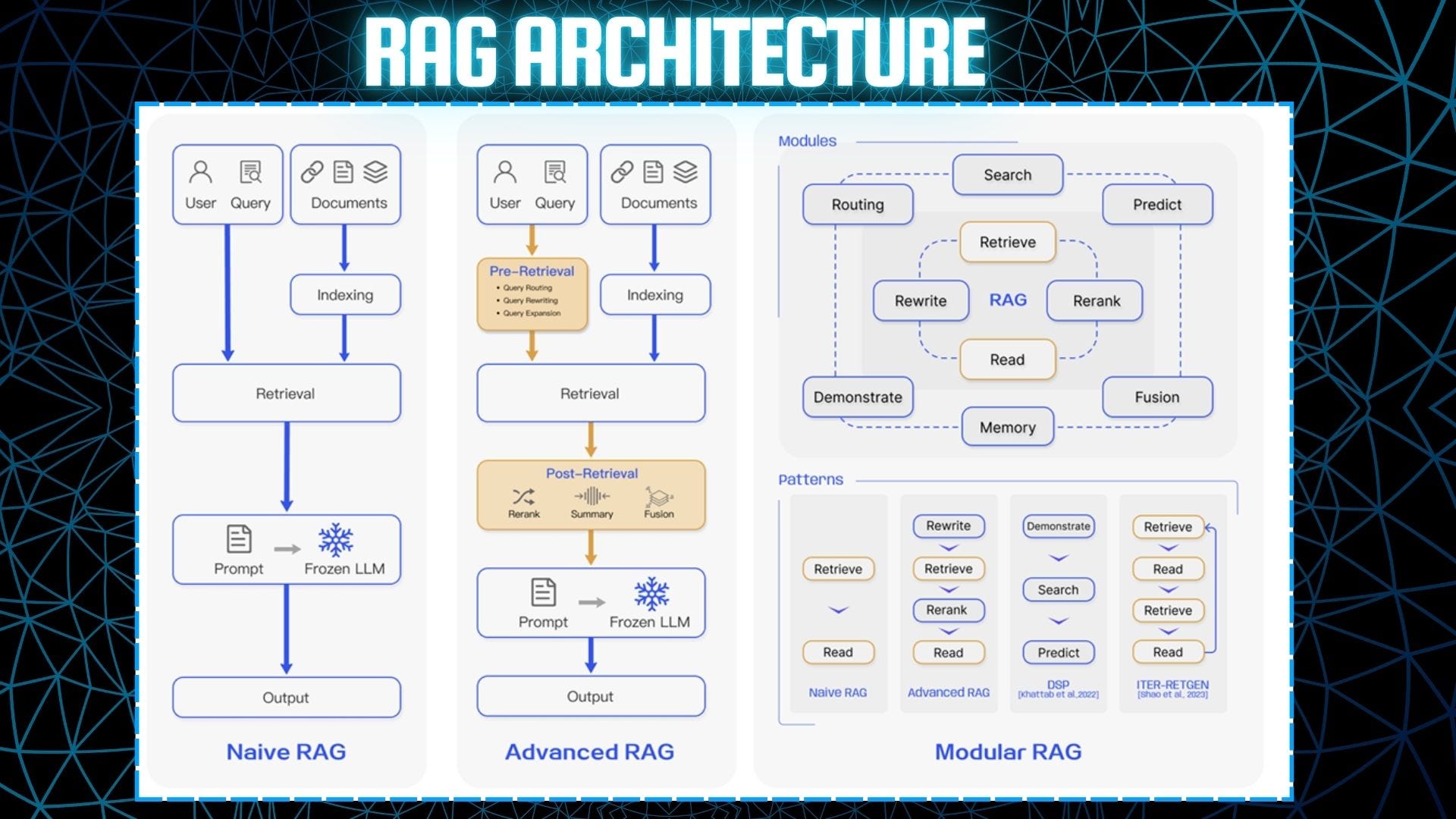
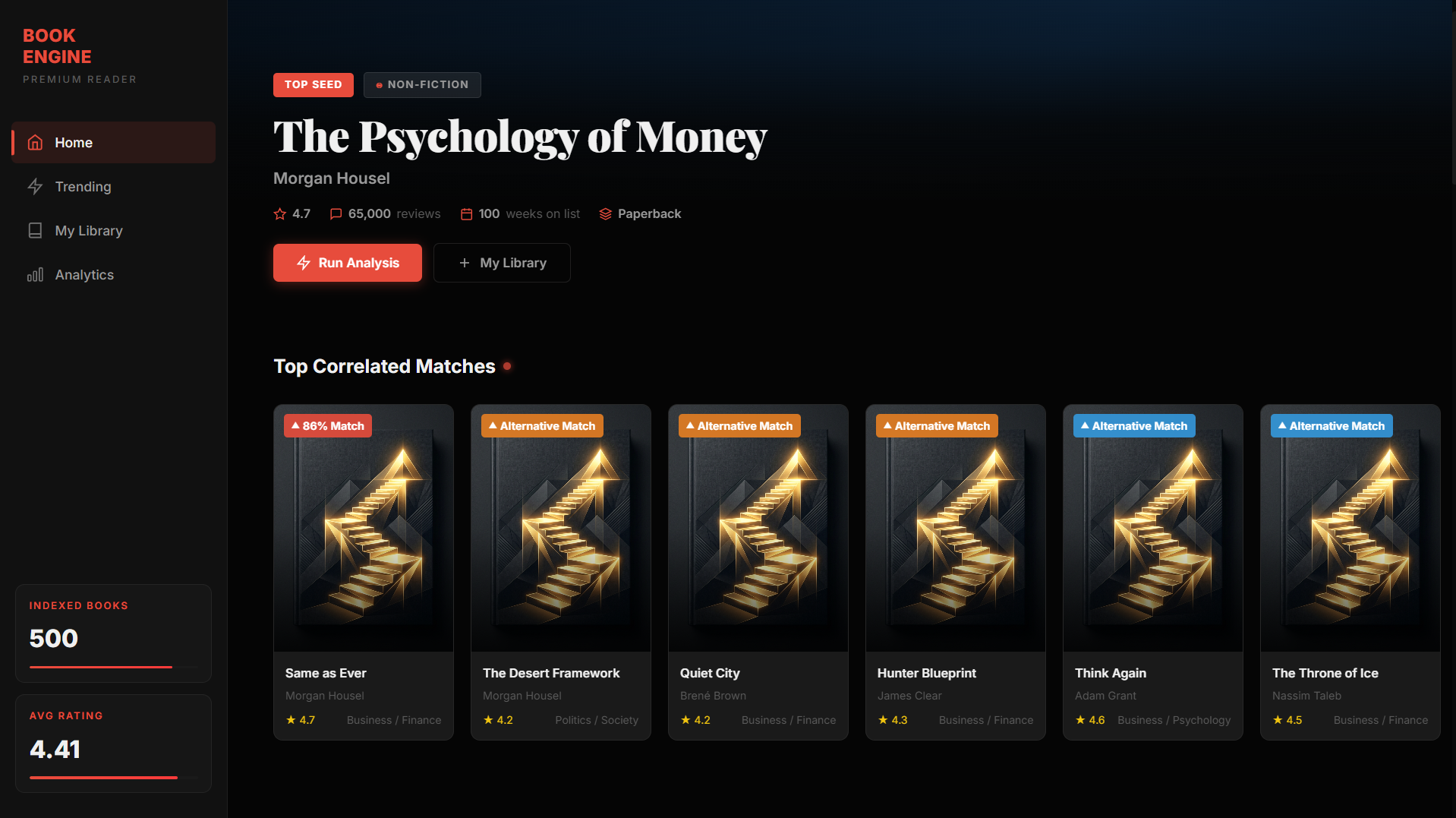
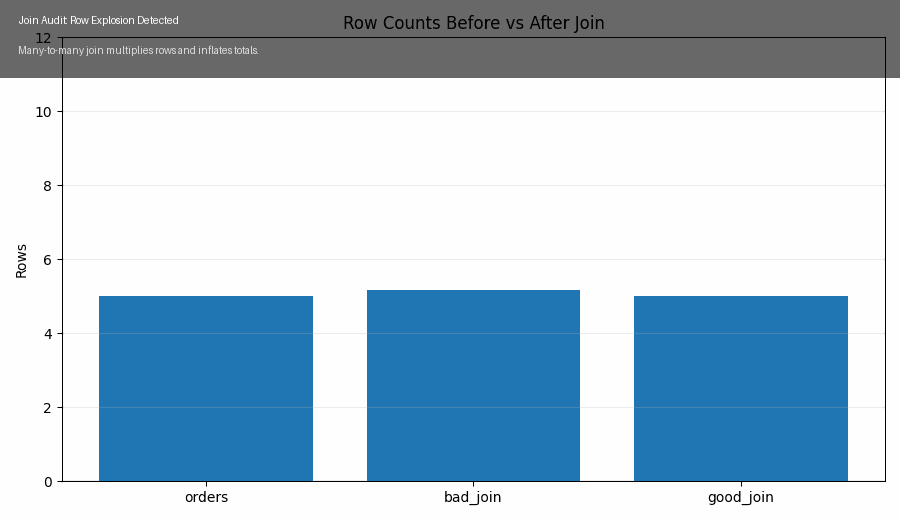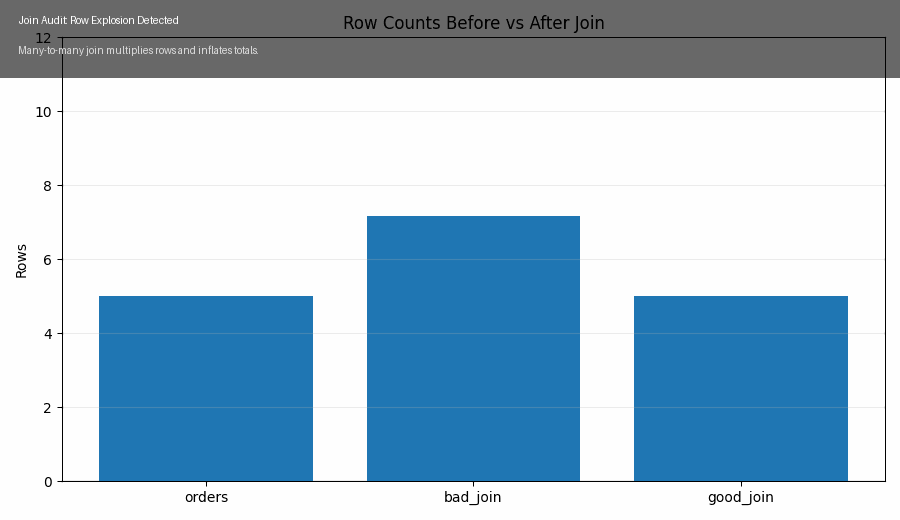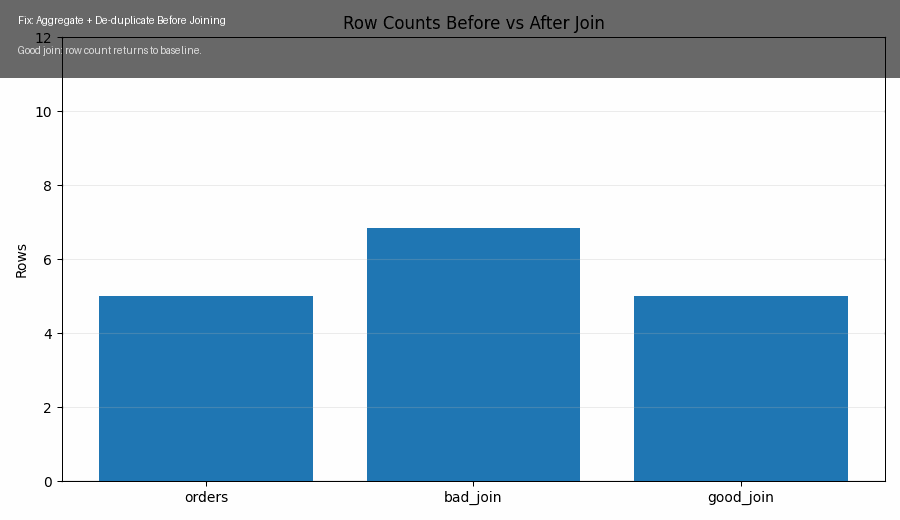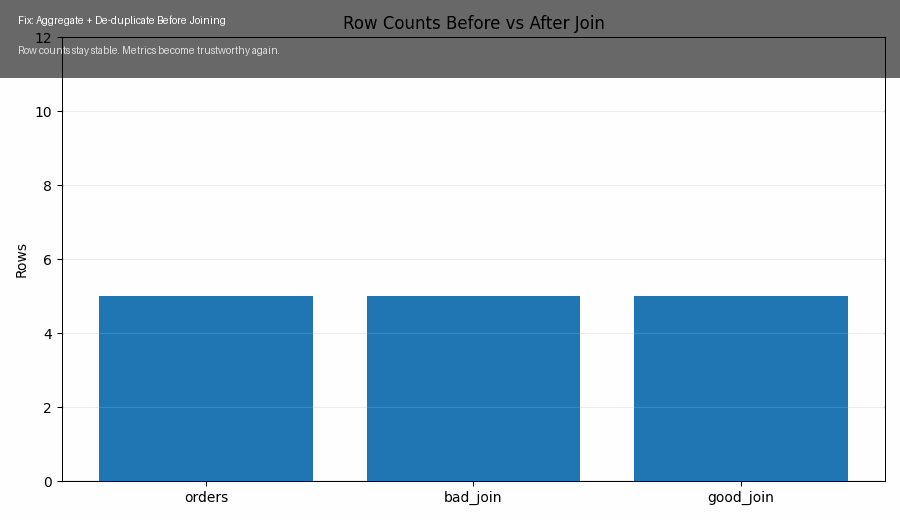
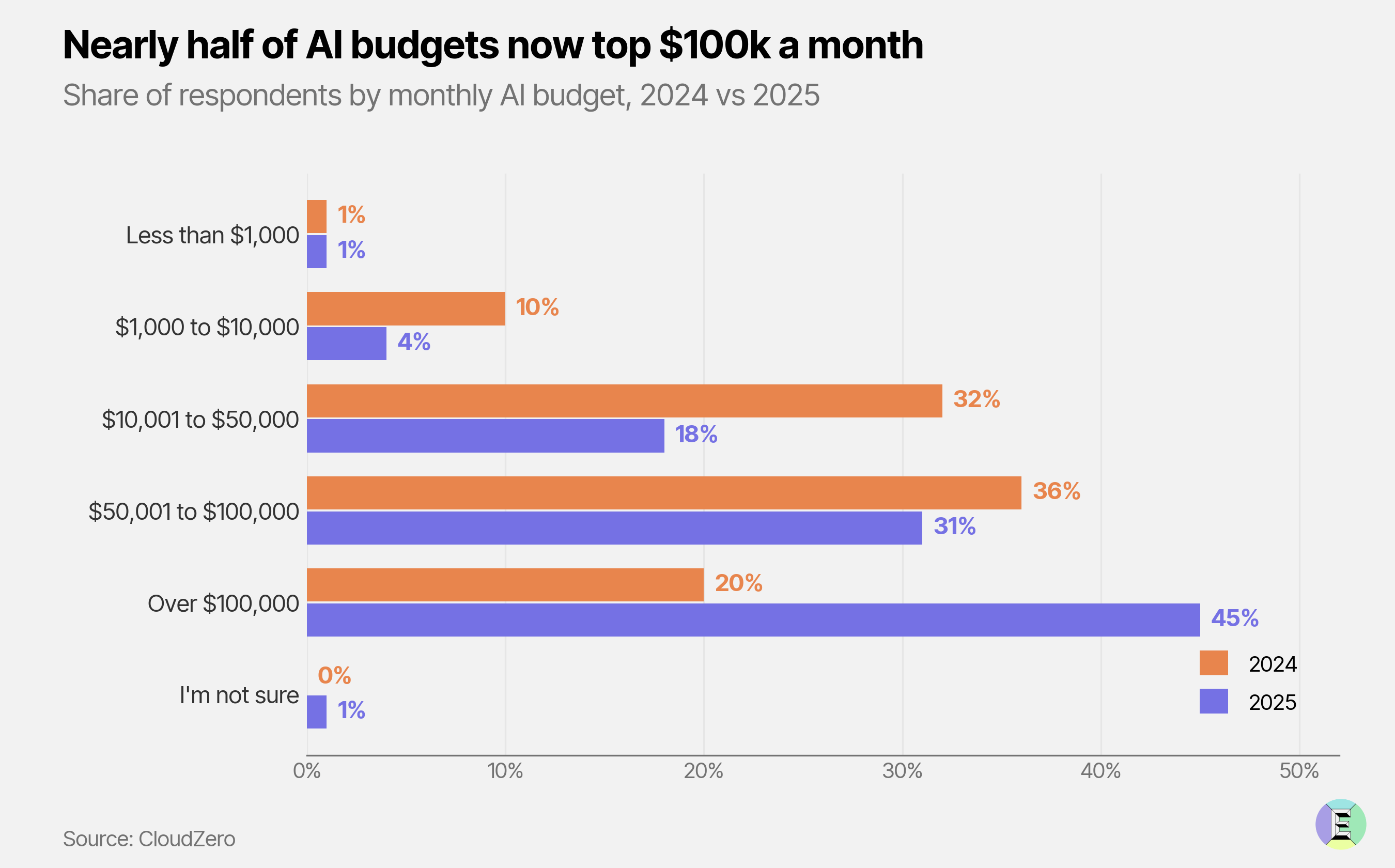
Statistics Concept — Monty Hall Paradox: When Intuition Fails but Bayesian Reasoning Prevails
This article explores the Monty Hall Paradox, a classic probability puzzle where intuition often leads to incorrect conclusions. It demonstrates how Bayesian reasoning, through a step-by-step probabilistic breakdown, graphical illustration, and Monte Carlo simulation using Python, can correctly solve the paradox. The piece highlights the power of formal statistical methods over common sense when dealing with complex probability scenarios. AI

IMPACT Explains a core statistical concept relevant to AI model reasoning and decision-making.