RE: https:// norden.social/@czottmann/11654 3661621806436 # Tensorix via # Cortecs keeps delivering. # DeepSeek V4 Flash at 350 tps throughput, ~1.5s latency. <
DeepSeek V4 Flash, a new iteration of the DeepSeek V4 model, has demonstrated impressive performance metrics. It achieves a throughput of 350 tokens per second with a latency of approximately 1.5 seconds. This advancement is attributed to Tensorix and Cortecs, with implications for AI development in the EU. AI
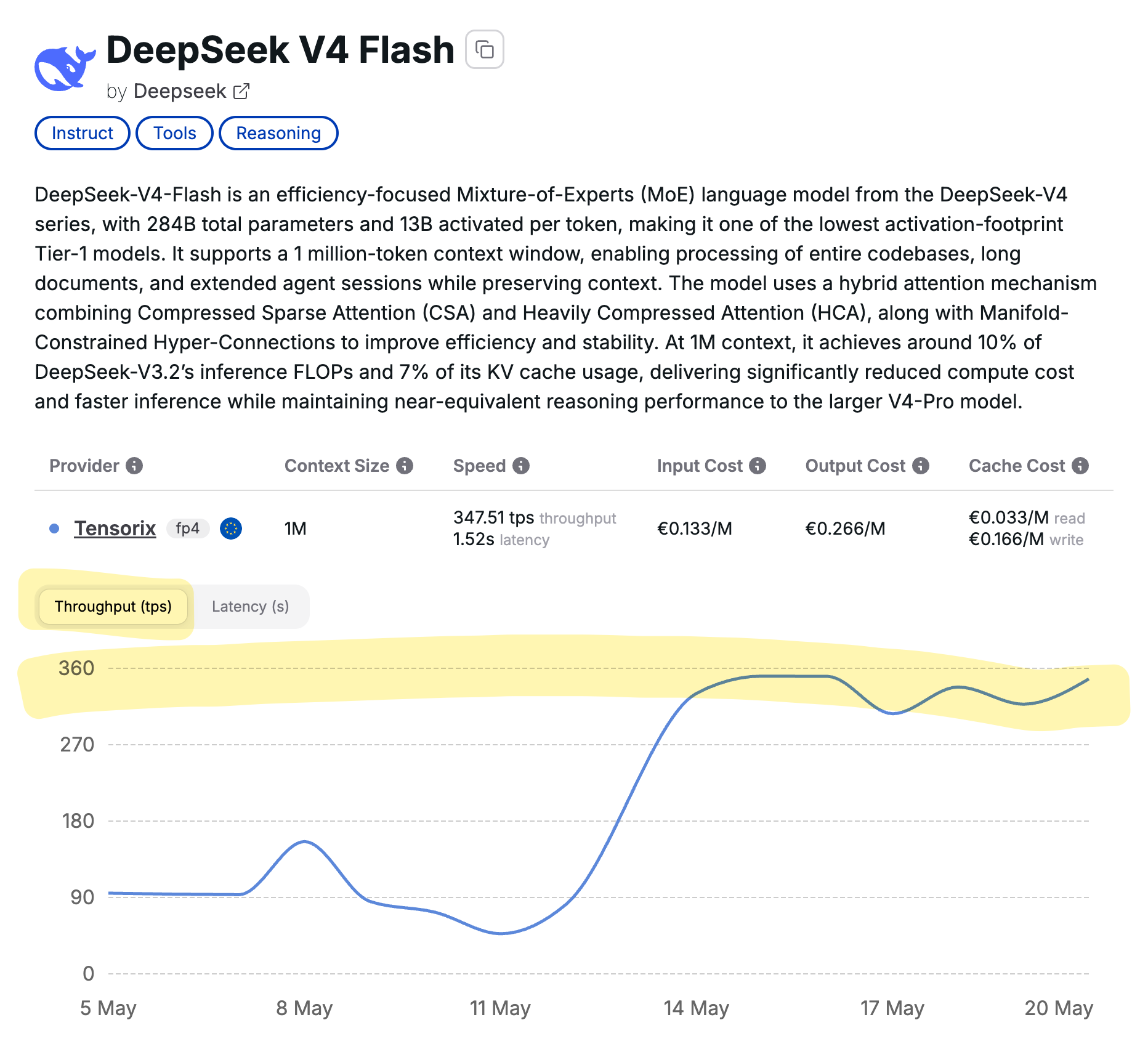
IMPACT New performance benchmarks for DeepSeek V4 Flash offer insights into LLM throughput and latency capabilities.