QLoRA Fine-Tuning of LLaMA 3.2–1B Instruct on a Healthcare Domain Dataset
A technical article details the process of fine-tuning the LLaMA 3.2–1B Instruct model using the QLoRA method. The fine-tuning was performed on a dataset specifically curated for the healthcare domain. This approach aims to adapt the general-purpose language model for specialized tasks within healthcare. AI
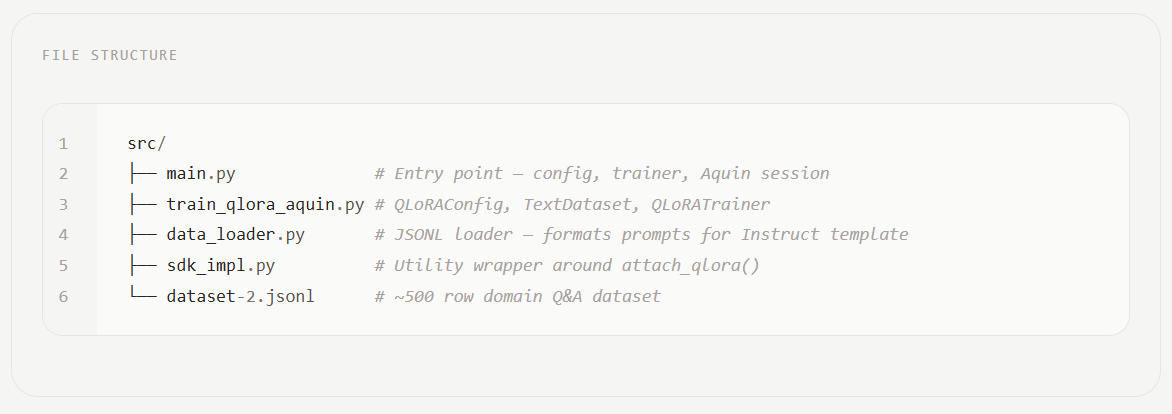
IMPACT Demonstrates domain adaptation techniques for open-source models, potentially improving their utility in specialized fields like healthcare.


