Sliding Windows Forget: Why Long-Running LLM Apps Need Memory Policy
A new prototype called LLM-Context-Optimization-Engine has been developed to address failures in long-running Large Language Model applications. These failures often stem from selecting the wrong context, rather than pure reasoning errors. The engine benchmarks various context selection policies, including sliding windows, full history, and retrieval methods, to determine which pieces of prior state are most relevant for the next model call. An importance-based selection policy demonstrated a high retention rate of critical facts within a limited budget, highlighting the need for memory policies over simple memory storage in persistent LLM applications. AI
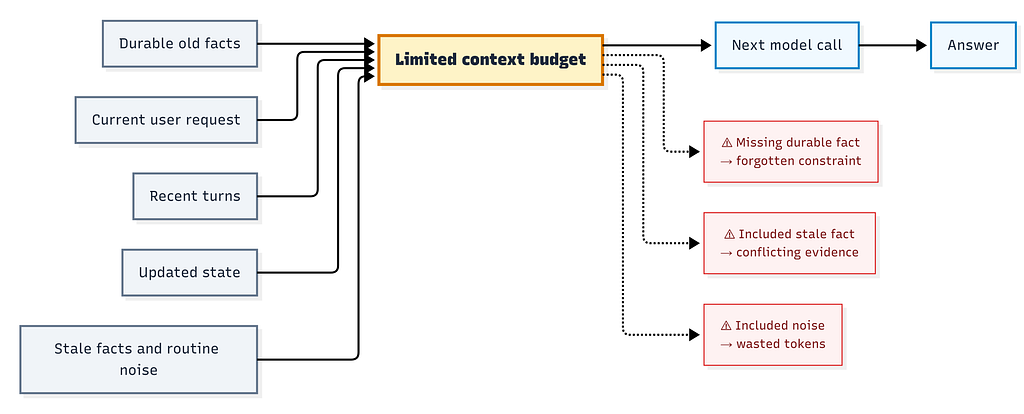
IMPACT Highlights the need for sophisticated memory policies in LLM applications to manage context effectively, crucial for agent development.