We Benchmarked the Most Popular Code Search Tools. We Beat All of Them.
A new code search tool called knowing has outperformed established competitors like CodeGraph, GitNexus, and Gortex in benchmarks. Knowing utilizes a novel approach involving random walks on a content-addressed call graph, which prioritizes structural relevance over simple keyword matching. This method resulted in significantly higher precision, faster query times, and more efficient agent integration compared to other tools, effectively eliminating nearly all irrelevant results. AI
IMPACT Sets a new standard for code retrieval precision and speed, potentially improving developer productivity and AI agent efficiency.
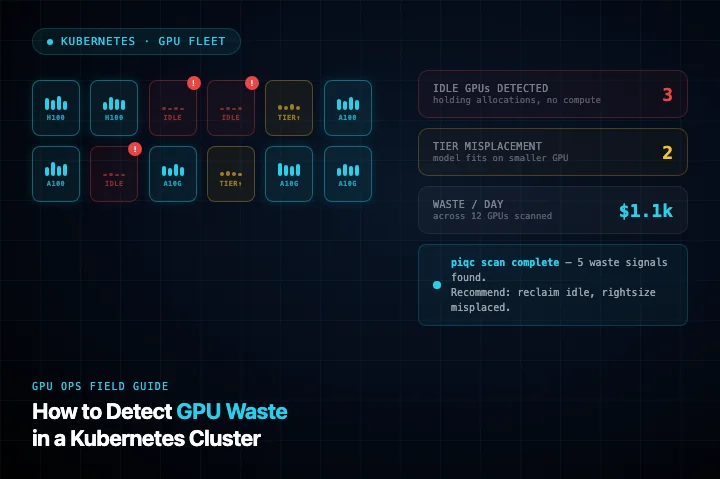
![Enterprise AI Agent Foundation Can Be Built On-Premises or In The Cloud. Kubernetes Deployment To Bare Metal Also Possible. Nutanix .NEXT 2026 [PR] - Publickey https://www.yayafa.com/2807948/ #AgenticAi #AI #ArtificialGeneralIn](https://cdn.fosstodon.org/cache/media_attachments/files/116/636/313/939/741/083/original/adf6ed11a0f13bb6.png)