Harmfulness Directions in OLMo
Researchers have analyzed the development of harmfulness representations within the OLMo 3 7B model during its training process. They identified distinct but related linear activation directions for various harmfulness subcategories, observing that these directions evolve and stabilize over time. The study found that in-distribution evaluations can be misleading, emphasizing the need for out-of-distribution testing, and demonstrated that late-stage training directions can effectively steer the model's behavior. AI
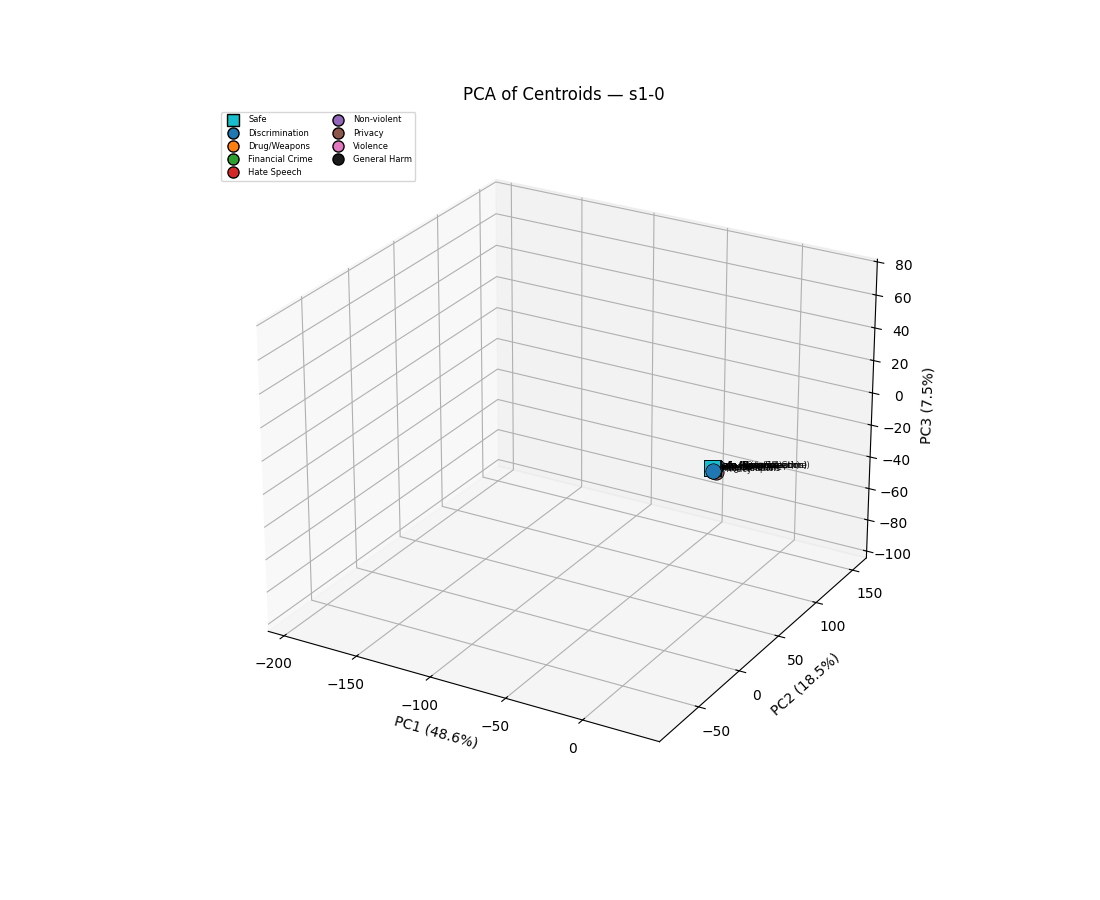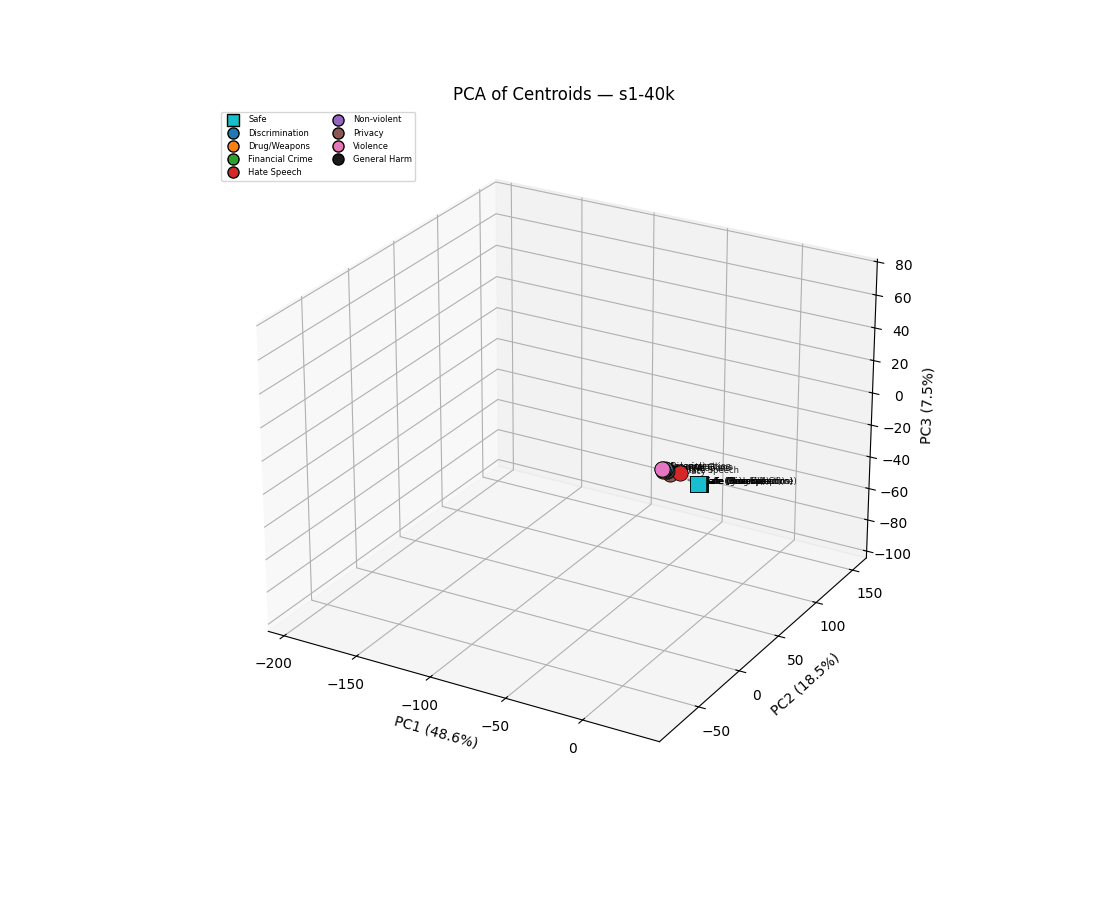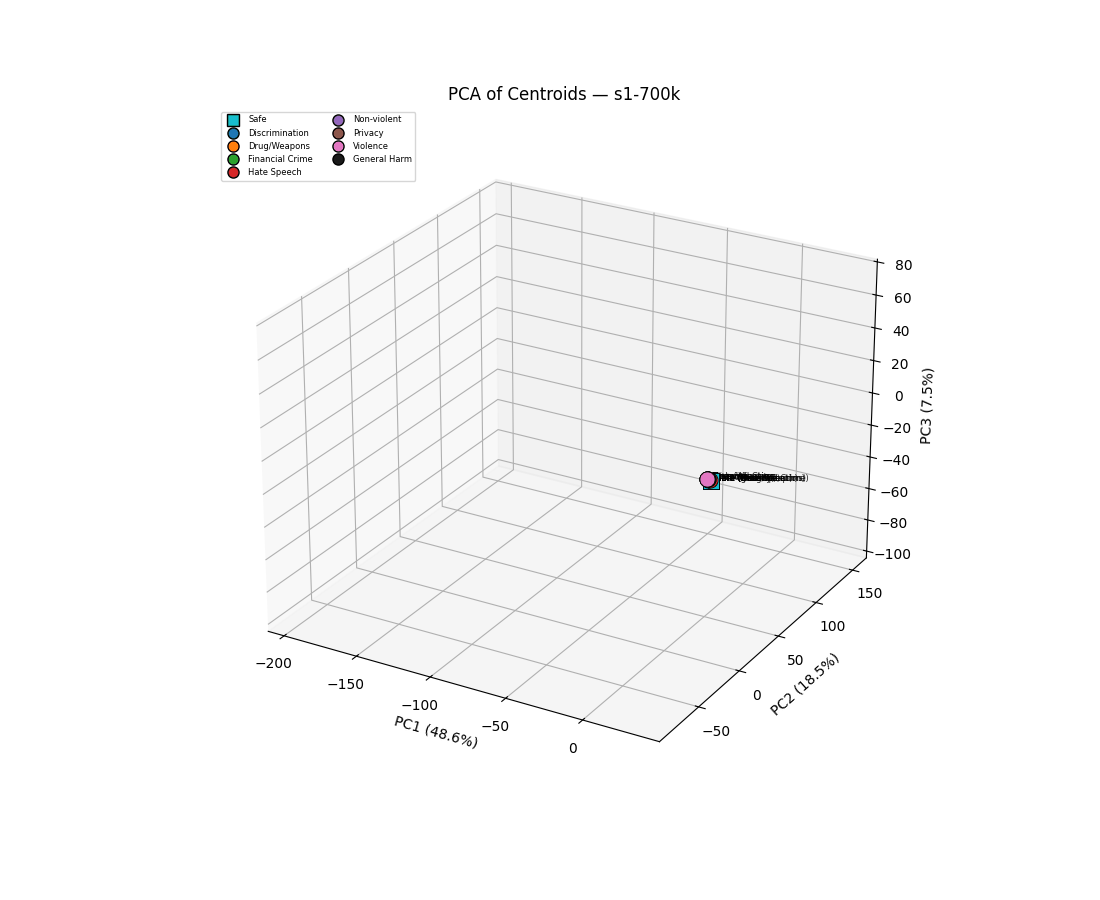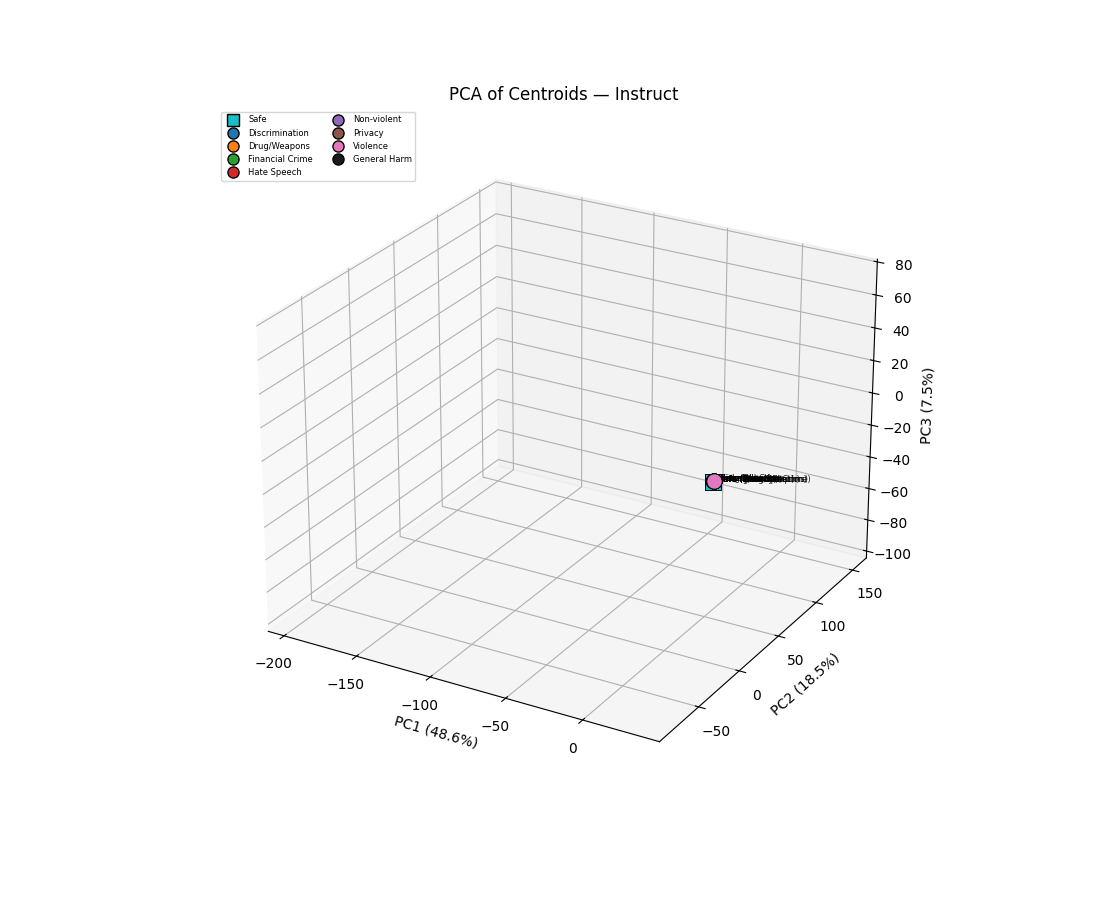
IMPACT Reveals insights into how harmful concepts are represented and evolve during LLM training, potentially informing future safety research.