Understanding LangChain, LangGraph, RAG, and MCP
Multiple dev.to articles detail how to build AI agents using LangGraph, a workflow system from LangChain. The posts provide templates for common agent patterns, including Retrieval-Augmented Generation (RAG) for document querying, multi-tool agents that can plan and execute tasks, and human-in-the-loop workflows requiring user review. These templates illustrate LangGraph's architecture with nodes, edges, and state management for creating complex, stateful AI applications. AI
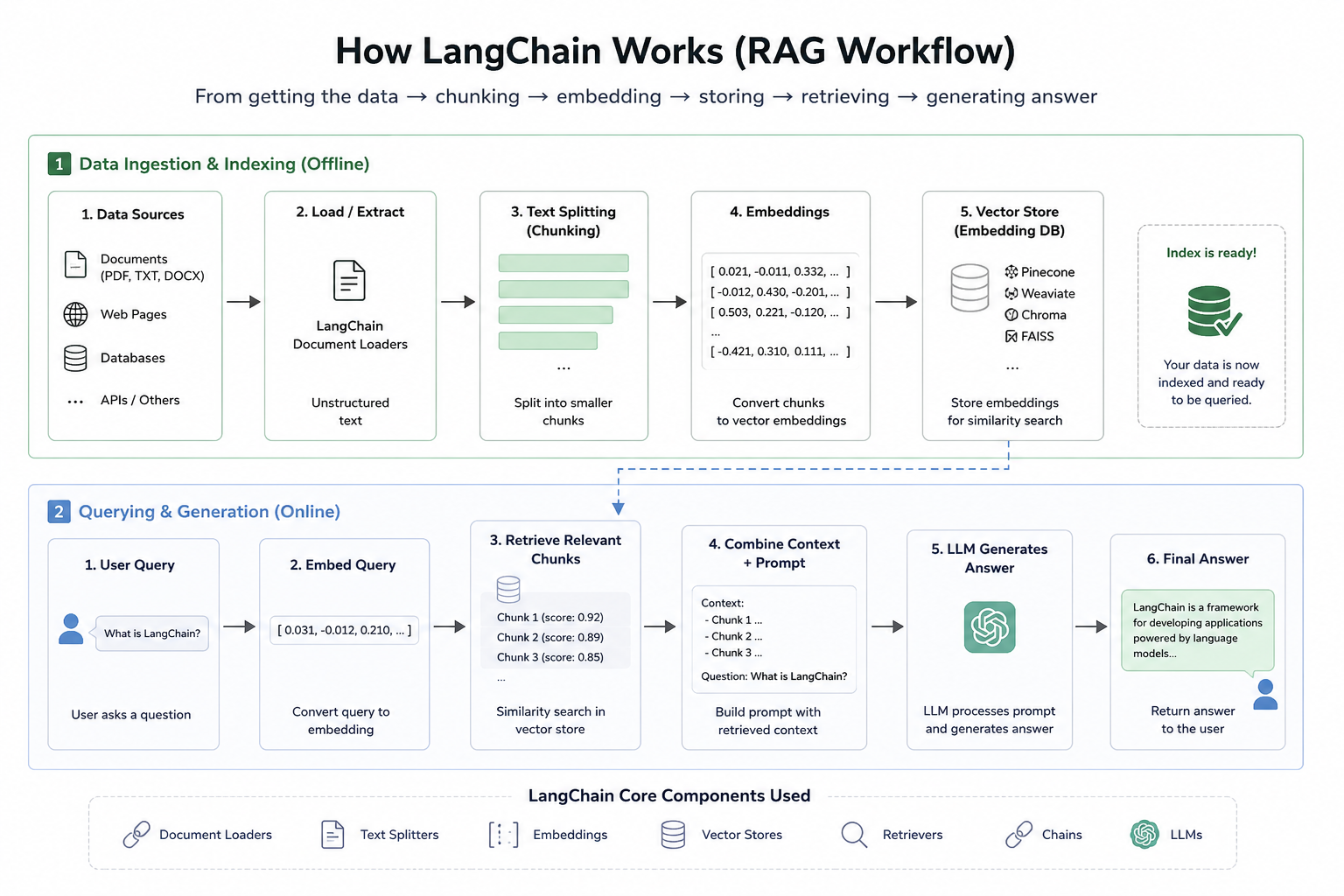
IMPACT Provides practical templates and code examples for building complex AI agents, accelerating development for RAG, multi-tool, and human-in-the-loop applications.