Frontier post-training recipe review with Finbarr Timbers
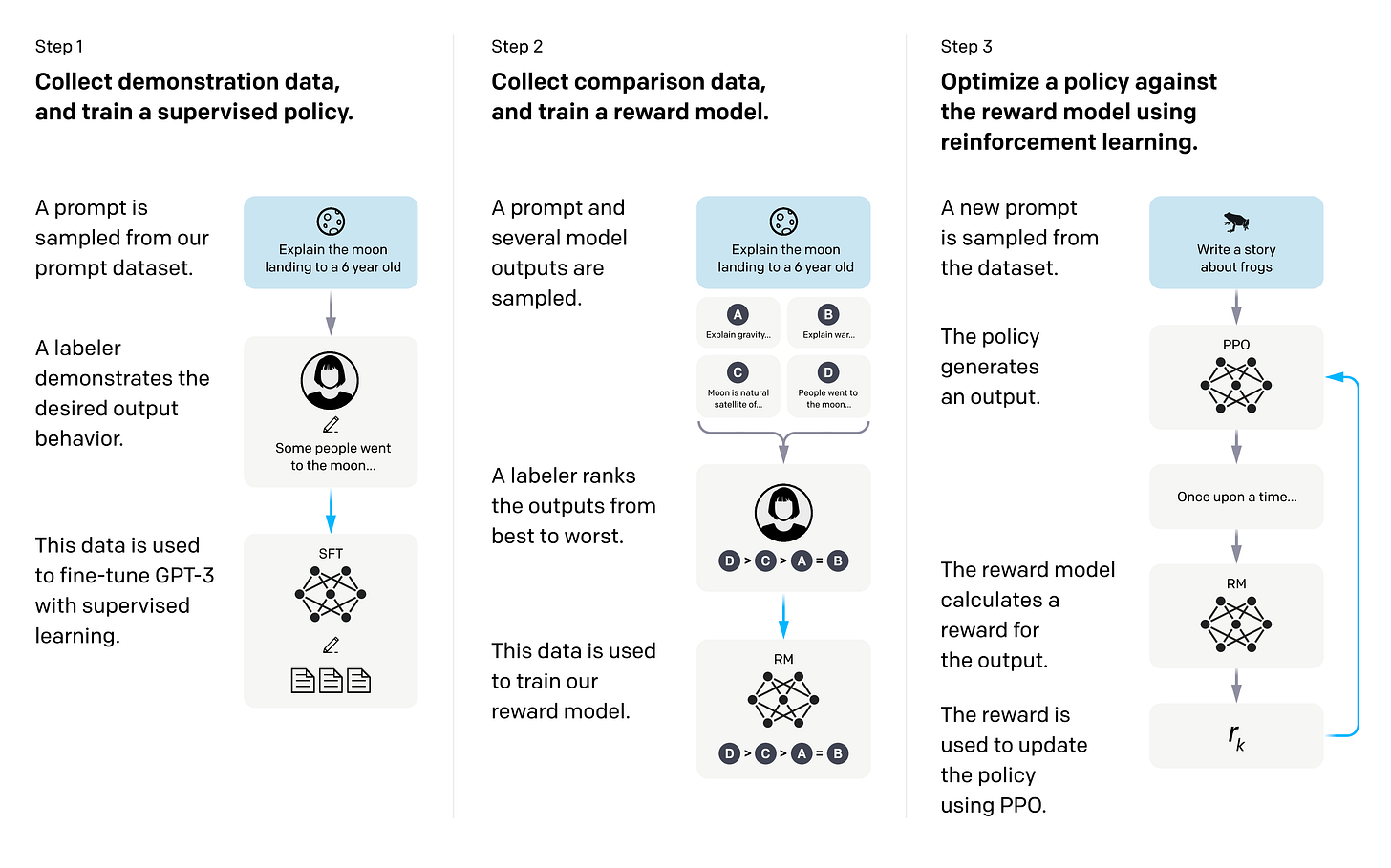
A review of post-training recipes for large language models highlights significant evolution in the past year. Historically, models followed a pipeline of Supervised Fine-Tuning (SFT), reward modeling, and Reinforcement Learning (RL). However, recent advancements in 2024 and projections for 2025-2026 indicate a shift towards more complex, multi-stage processes. These include Direct Preference Optimization (DPO) and Reinforcement Learning from AI Feedback (RLAIF), with a notable emergence of Multi-teacher On-Policy Distillation (MOPD) for frontier models. AI
IMPACT Understanding evolving LLM training methodologies is crucial for optimizing model performance and efficiency.