Build an AI Contract Intelligence System: OCR + Hybrid RAG + LangGraph to Extract Key Terms…
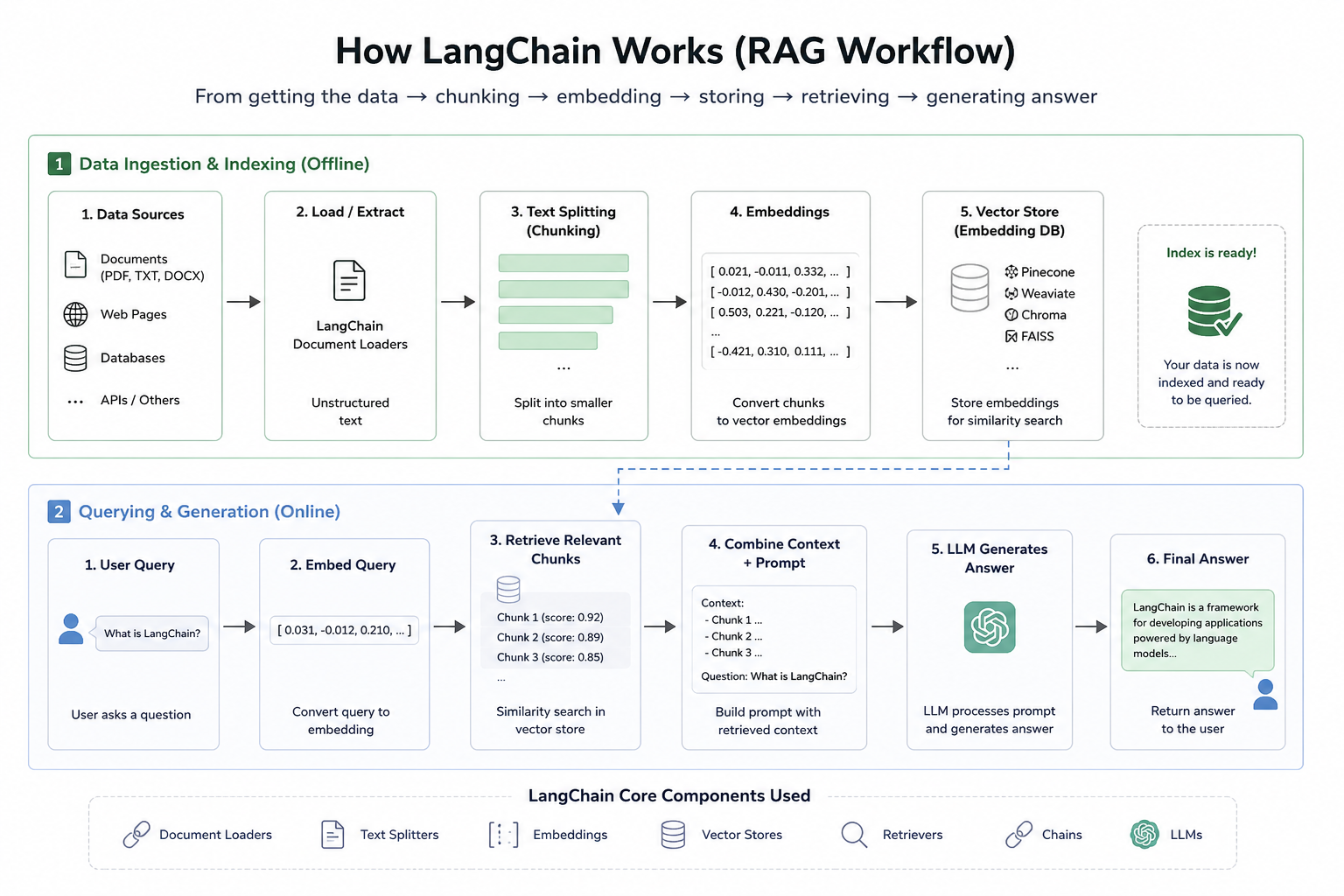
This article details how to build an AI-powered system for contract intelligence, automating the extraction of key terms from various document formats. The system utilizes a combination of Optical Character Recognition (OCR) with PaddleOCR, hybrid retrieval methods like FAISS and BM25, and the GPT-4o model within a LangGraph pipeline. This approach aims to transform unstructured contract data into structured reports, addressing issues like missed deadlines, financial leakage, and compliance risks. AI

IMPACT Enables automated extraction of critical information from contracts, improving efficiency and reducing risks for legal, finance, and operations teams.