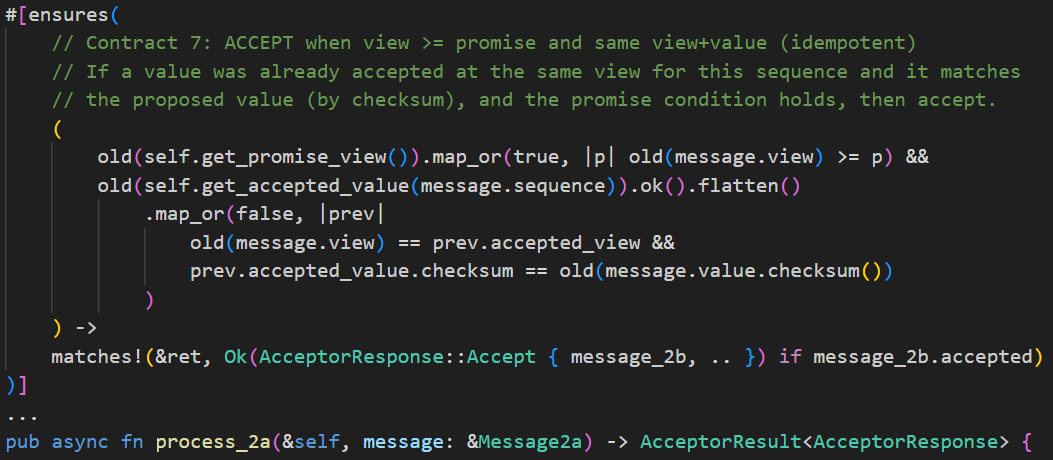
Formal Verification Gates for AI Coding Loops
A new methodology called Structural Backpressure aims to improve the reliability of AI-generated code by shifting enforcement of critical rules from AI prompts to the underlying code substrate. This approach uses deterministic checks like compilers and type systems, rather than relying on AI models to remember and apply complex invariants. The goal is to make AI coding loops more stable by providing concrete feedback mechanisms, moving beyond simply trying to make AI models 'smarter'. AI
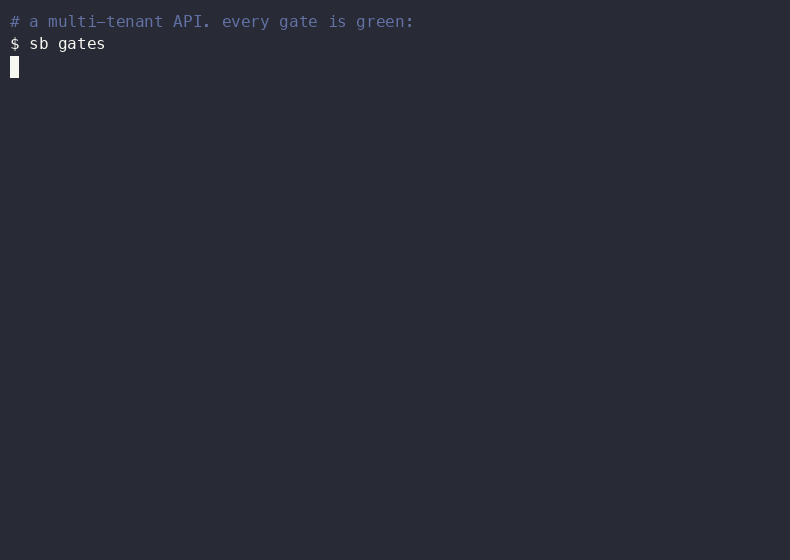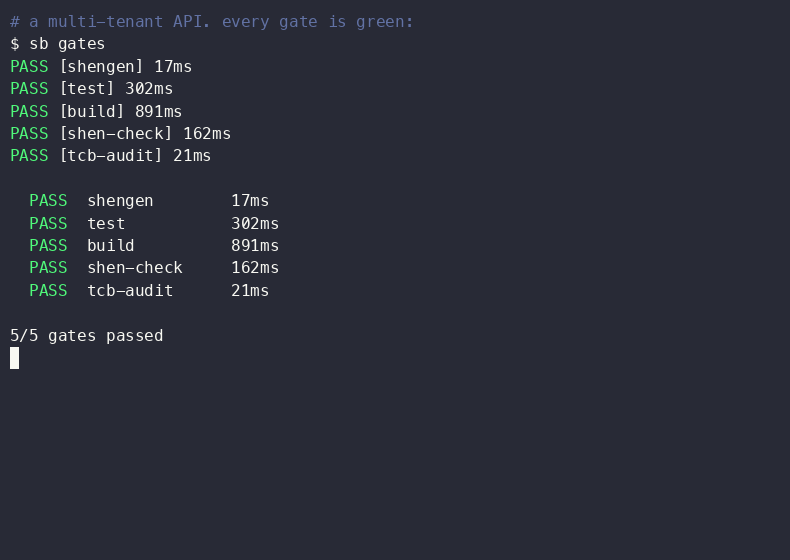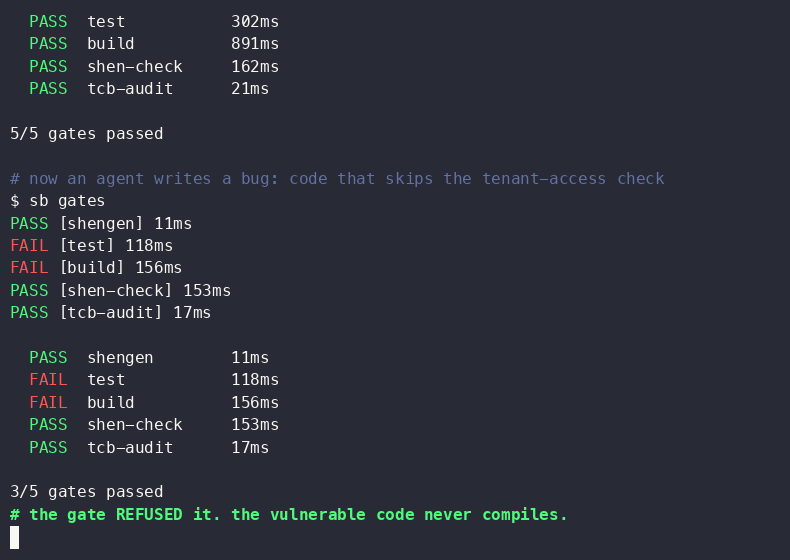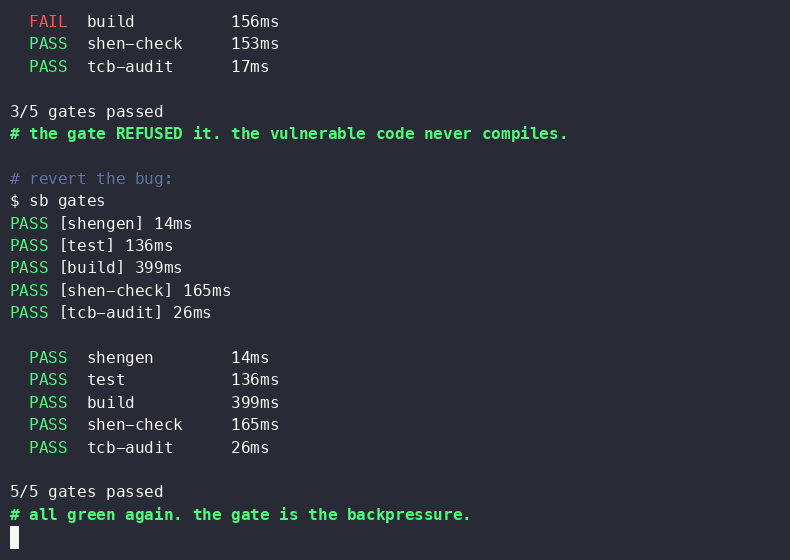
IMPACT Enhances AI code generation reliability by using deterministic checks, potentially reducing bugs and improving stability in AI-assisted development.