WER Is Not Enough: How I Benchmarked and Fine-Tuned ASR for Indian Banking
This article details the process of fine-tuning an Automatic Speech Recognition (ASR) system specifically for the unique challenges of Indian banking calls. The author spent three weeks experimenting with multiple models to address issues like diverse accents and technical jargon. The goal was to create a functional ASR pipeline tailored to this niche application. AI
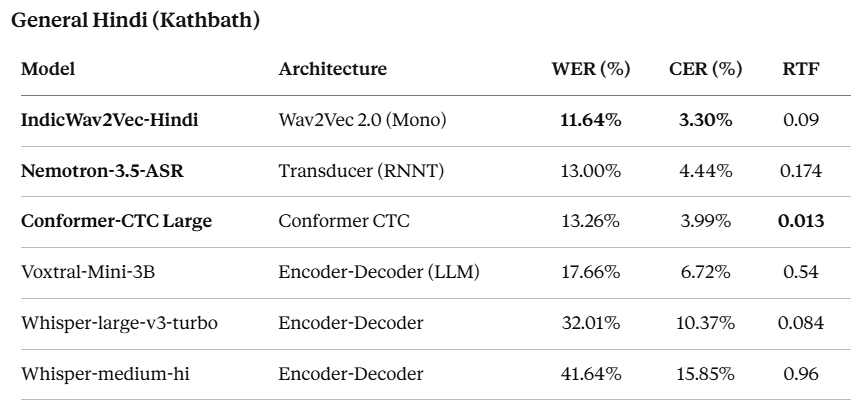
IMPACT Demonstrates the need for specialized ASR models in specific industries, highlighting challenges beyond general-purpose systems.