Accelerate LLM model loading and increase context windows with GPUDirect on Amazon FSx for Lustre and TurboQuant
AWS has introduced a new method to significantly speed up the loading of large language models onto GPU instances. By leveraging NVIDIA GPUDirect Storage (GDS) with Amazon FSx for Lustre, model weights can be loaded directly into GPU memory, bypassing the CPU and PCIe bus. This optimization reduces model loading times from minutes to seconds, thereby decreasing the total time to first token (TTFT) and making expensive GPU resources available much faster for inference. AI
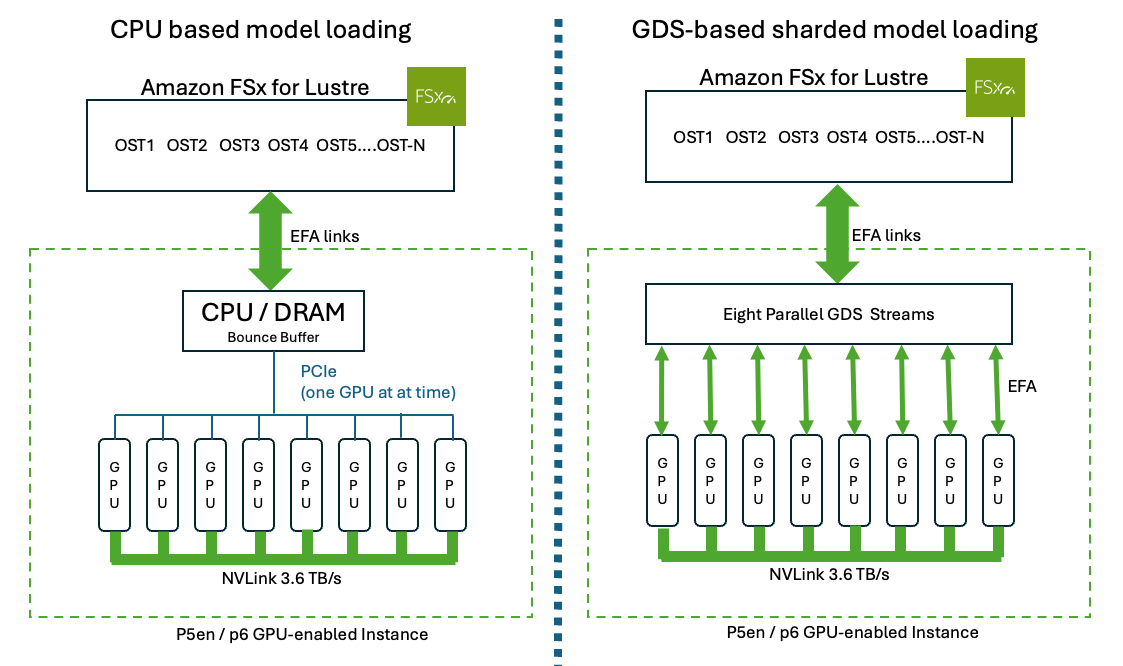
IMPACT Accelerates LLM deployment by drastically reducing model load times, enabling faster iteration and inference.