3-Part Series: LLM Latency in Production (Part 1)
This article explains that the primary bottleneck for LLM inference in production is often the model's raw speed on the GPU, rather than serving logic or network overhead. It details how LLM inference, particularly during the decode phase, is heavily bound by memory bandwidth due to the large size of model weights and the need to stream data. The piece highlights quantization, such as INT8, as a highly effective optimization technique that reduces memory footprint and improves bandwidth efficiency with minimal quality loss. AI
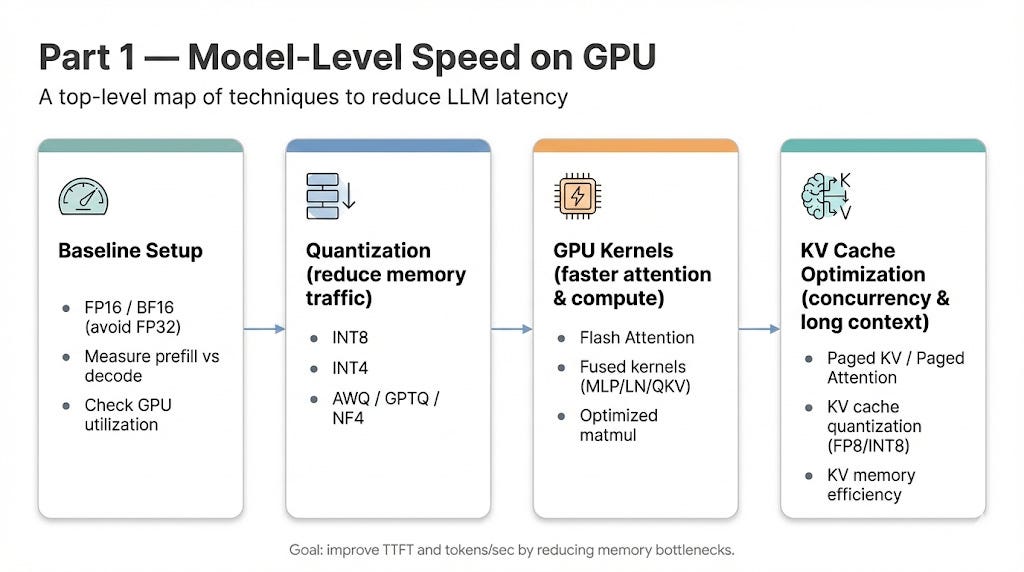
IMPACT Optimizing LLM inference speed is crucial for reducing operational costs and improving user experience in production environments.