Shipping a Fine-Tuned 35B MoE Model to SageMaker Without Burning the Budget.
This article details the process of deploying a fine-tuned 35B Mixture-of-Experts (MoE) model to Amazon SageMaker. It focuses on practical strategies for cost-effective deployment, specifically using QLoRA fine-tuning for a QWEN3.6-35B-A3B text-to-SQL model on a single-GPU endpoint. AI
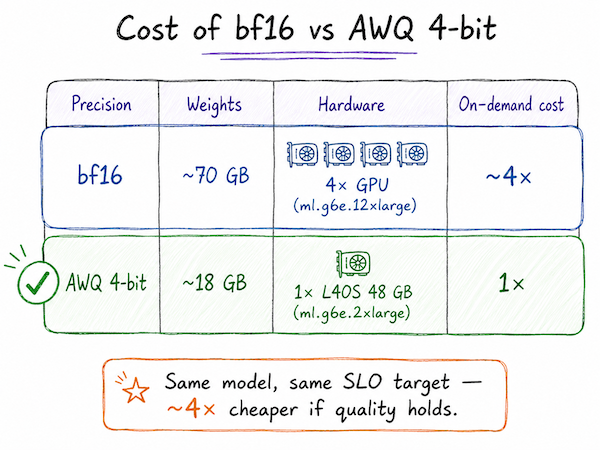
IMPACT Provides practical guidance for efficiently deploying large language models on cloud infrastructure.