Build an AI-Powered Equipment Repair Assistant Using Amazon Bedrock AgentCore https://www. byteseu.com/2095270/ # AI # ArtificialIntelligence
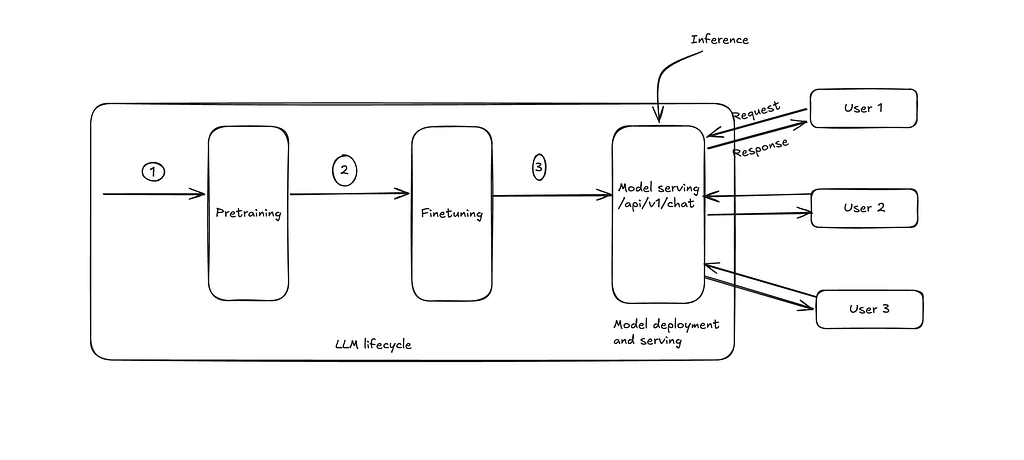
Amazon Web Services has introduced a new AI-powered assistant designed to streamline equipment repair processes. This tool, built using Amazon Bedrock AgentCore, helps technicians and farmers diagnose issues, identify necessary parts, and access repair documentation through natural language queries. The system integrates various AWS services, including a knowledge base for RAG, memory for conversation persistence, and authentication via Amazon Cognito, to provide a comprehensive solution for reducing downtime and repair costs. AI

IMPACT Streamlines equipment repair diagnostics and part identification, potentially reducing technician downtime and costs.