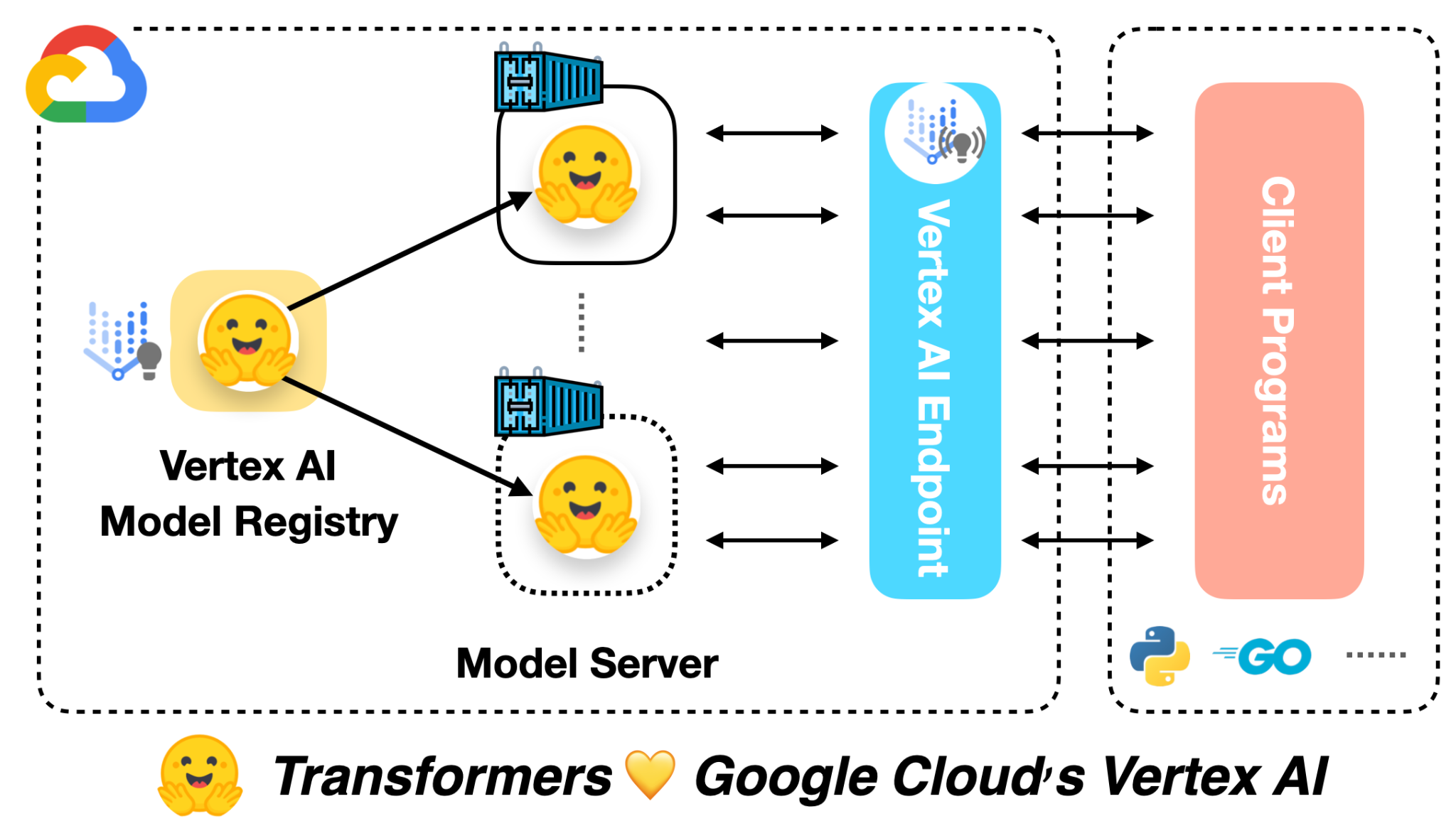
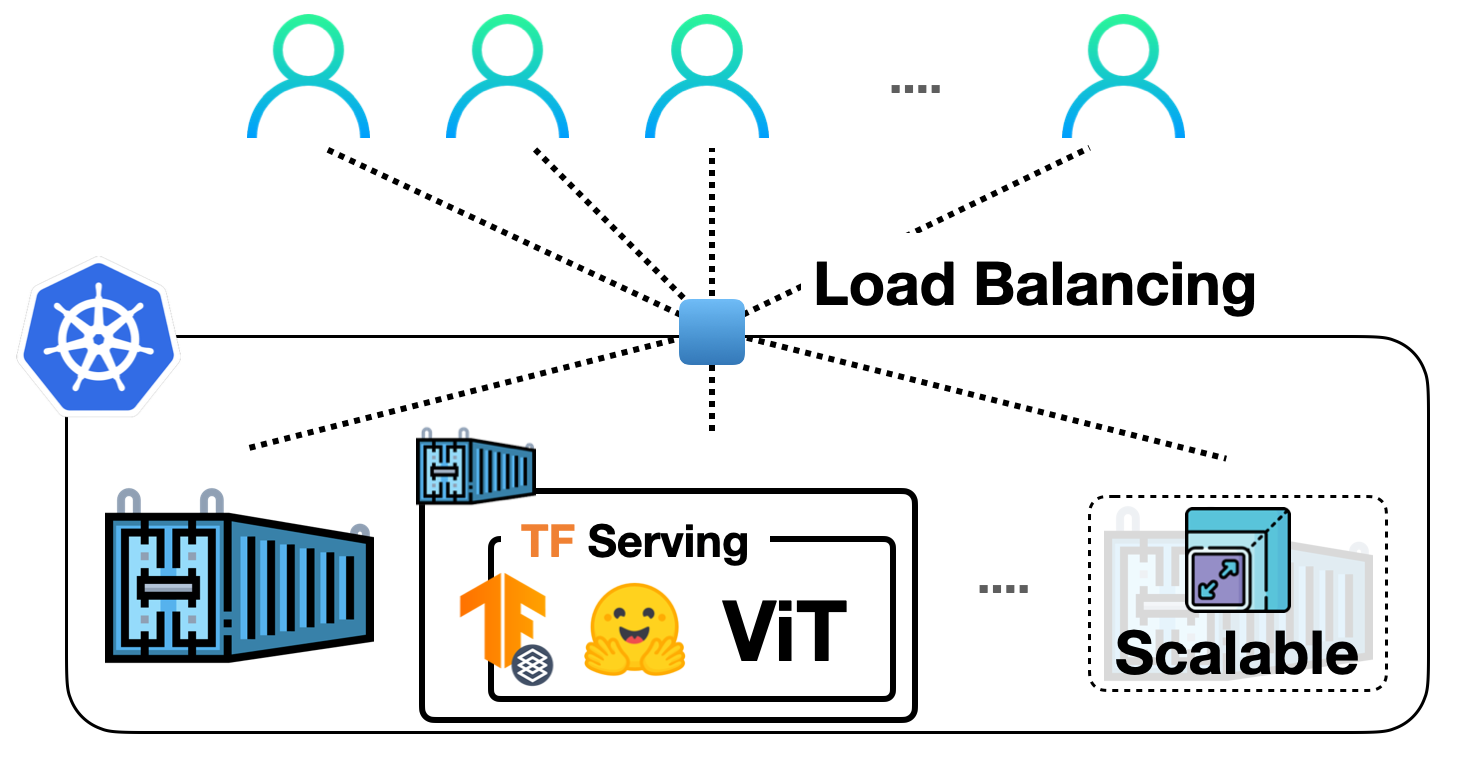
How 🤗 Accelerate runs very large models thanks to PyTorch
Hugging Face's Accelerate library now supports running very large language models by leveraging PyTorch's fully sharded data parallelism (FSDP). This integration allows for efficient distribution of model parameters, gradients, and optimizer states across multiple GPUs, significantly reducing memory requirements per device. The update enables users to train and infer with models that would otherwise be too large to fit into the memory of a single GPU, making advanced AI more accessible. AI