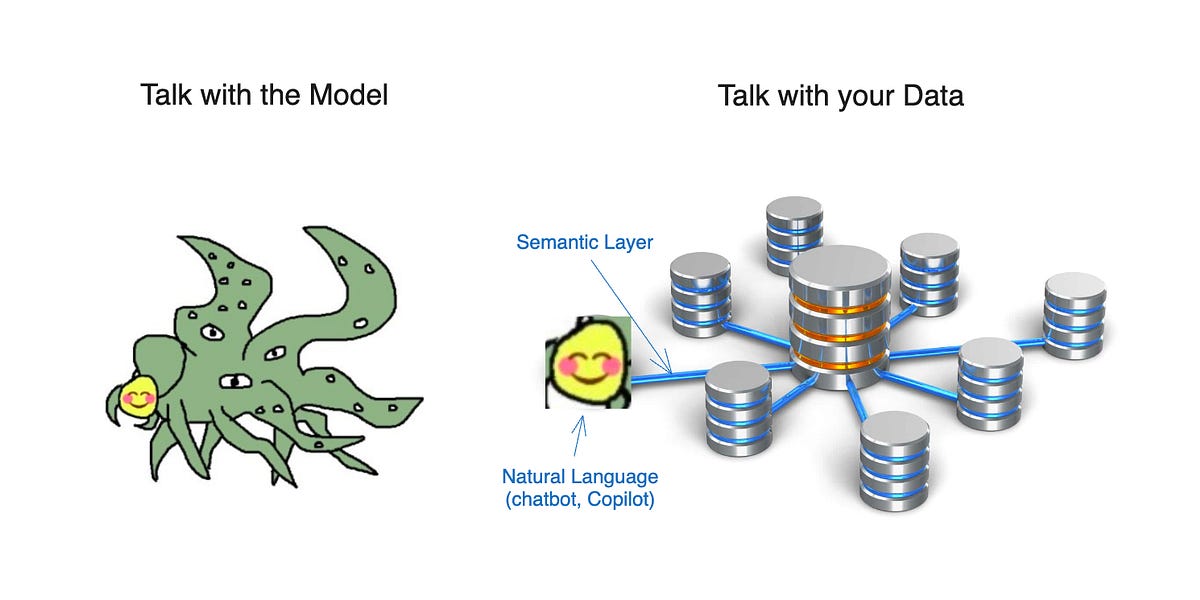
Self-hosting & scaling models
This podcast episode features Tuhin Srivastava from Baseten discussing the self-hosting and scaling of open-access AI models. The conversation delves into current trends in tooling and usage for these models, as well as common applications. The growth of generative AI and its impact on the ecosystem of self-hosted models was also a key topic. AI