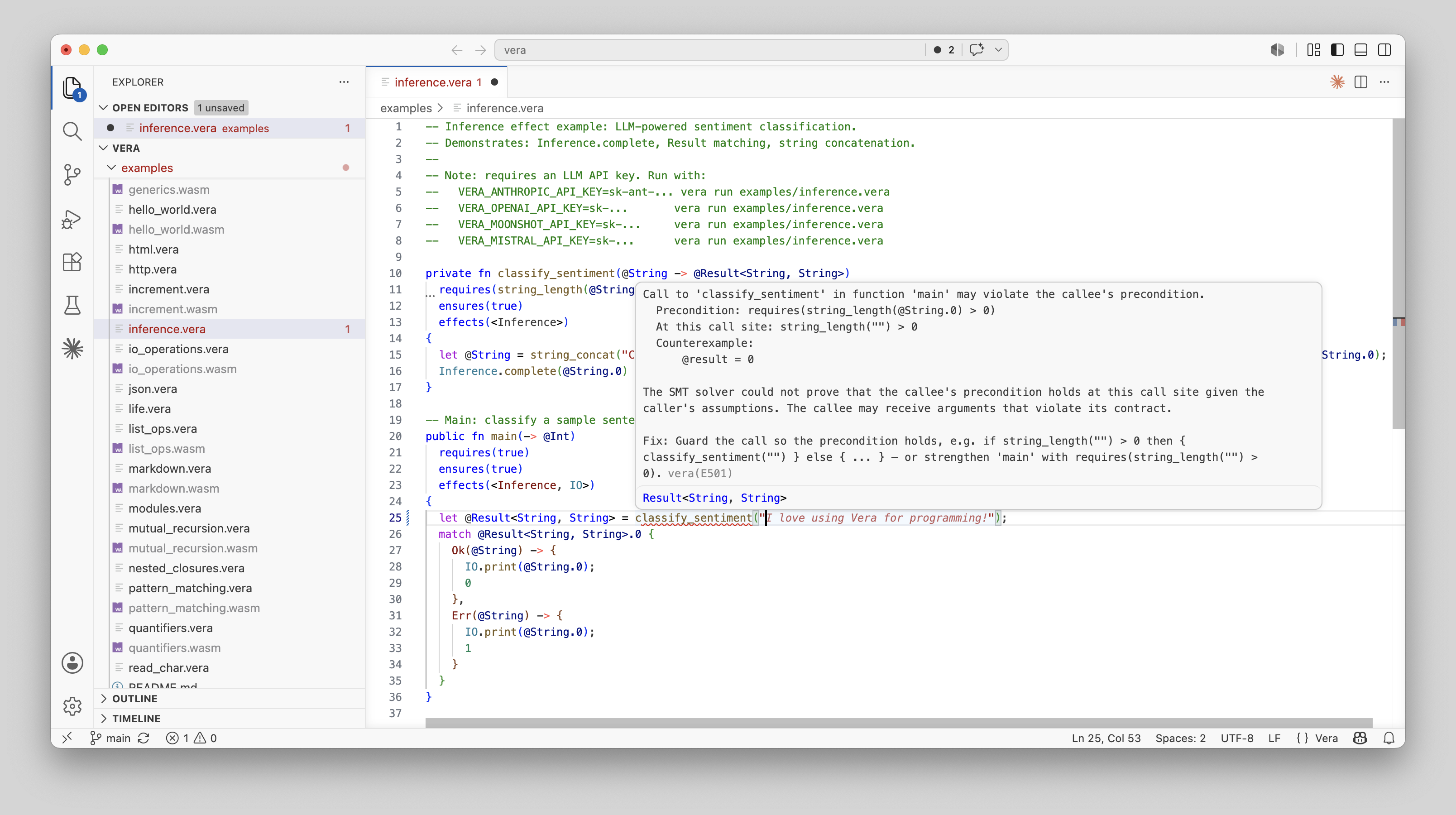
Multi-Objective Coevolution of Prompts and Templates for Circuit Approximation
Researchers have developed a novel co-evolutionary algorithm that uses a large language model (LLM) to design approximate multipliers for circuit approximation. This method automates the optimization process without needing domain-specific LLM training. The algorithm simultaneously evolves candidate circuits and prompt templates to guide the LLM's modifications, achieving better error-area trade-offs than existing optimized libraries for various design objectives. AI