Finetuning Qwen2.5-Math-1.5B
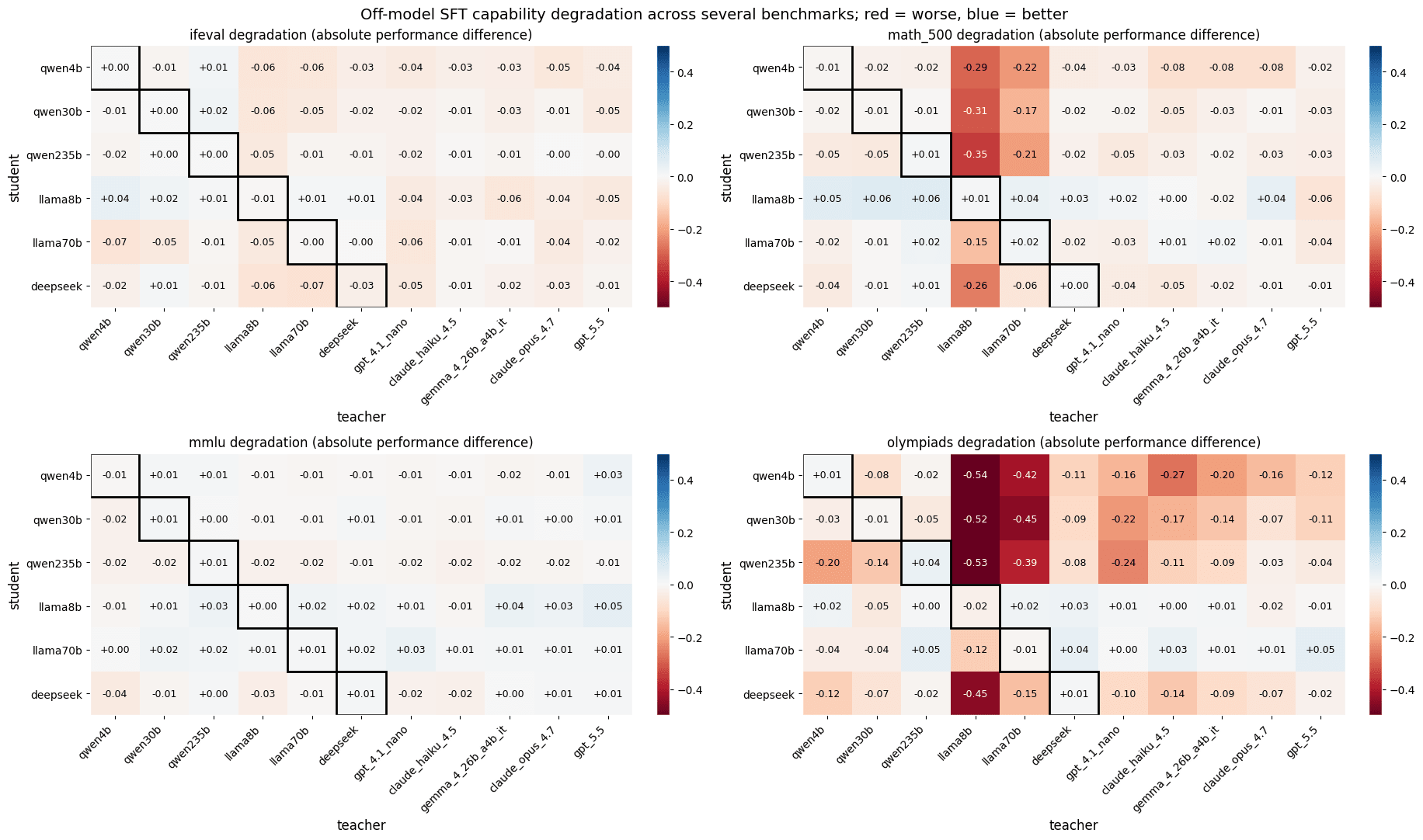
A technical guide details the process of fine-tuning the Qwen2.5-Math-1.5B model. The article outlines the steps involved in adapting this specific language model for mathematical tasks, likely to improve its performance or tailor it to particular applications. AI
IMPACT Provides a technical walkthrough for adapting a specific language model, potentially enabling others to replicate or build upon the fine-tuning process for specialized mathematical AI applications.