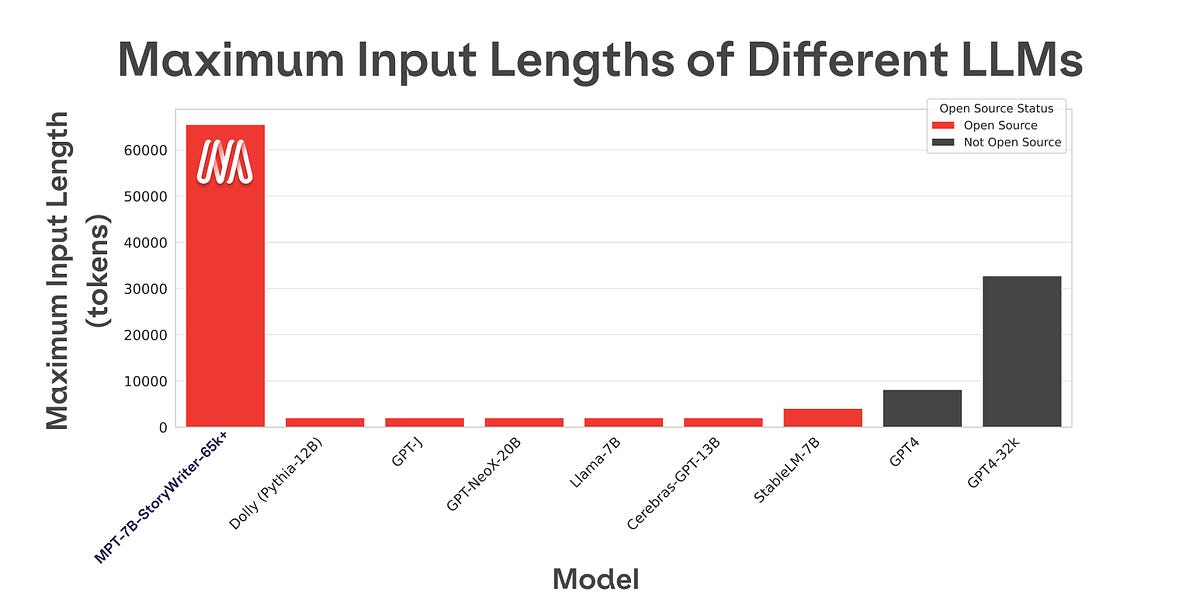
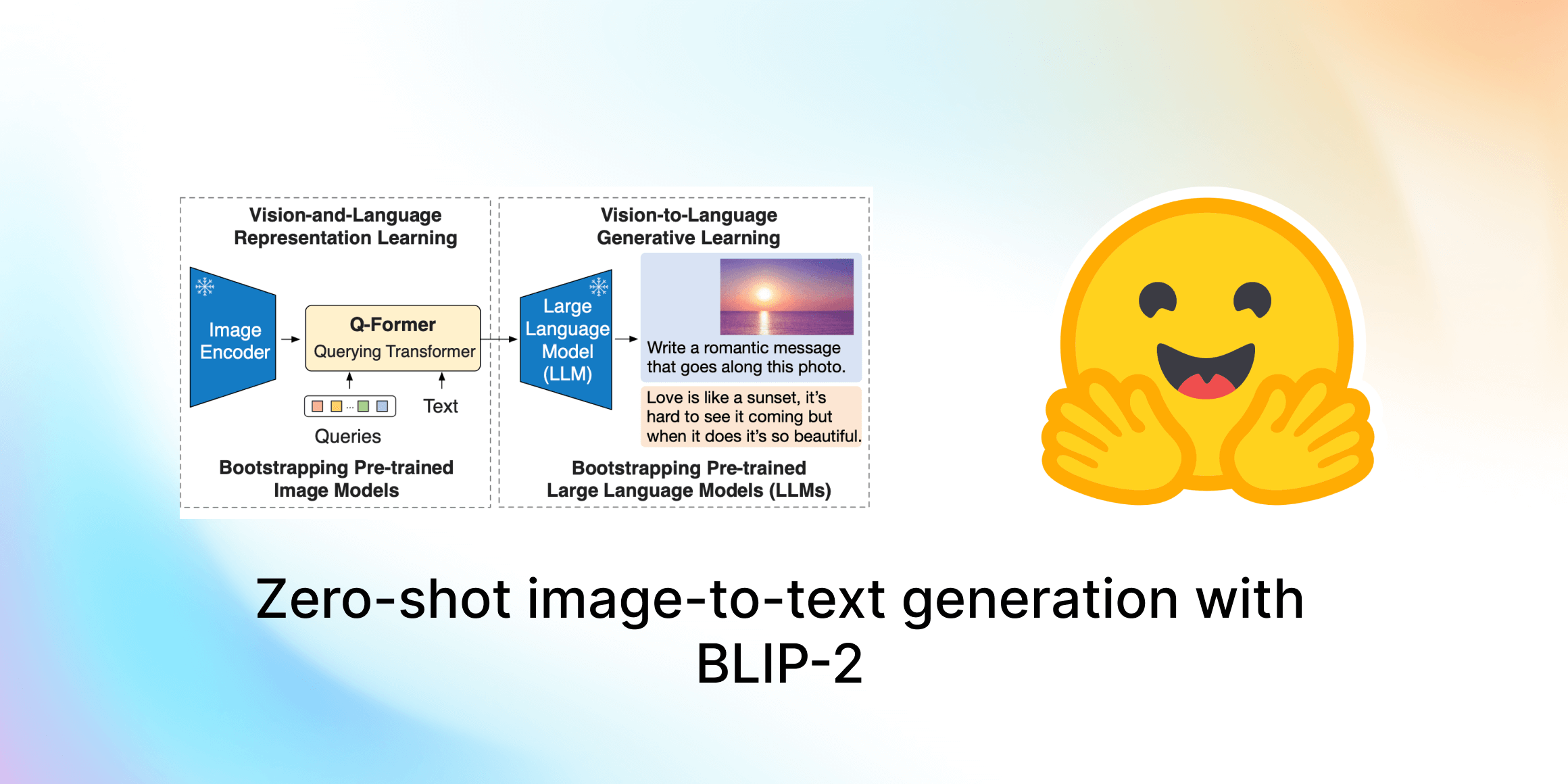
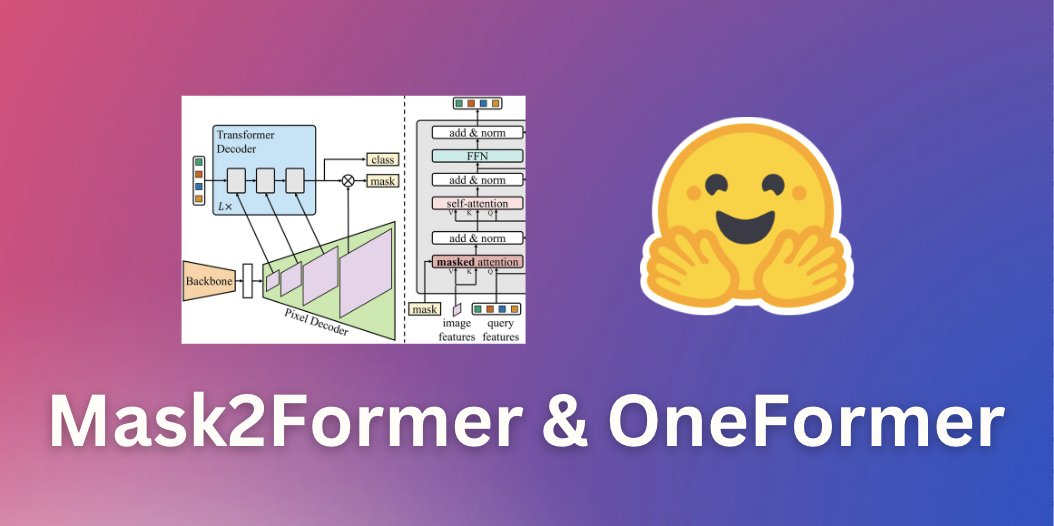
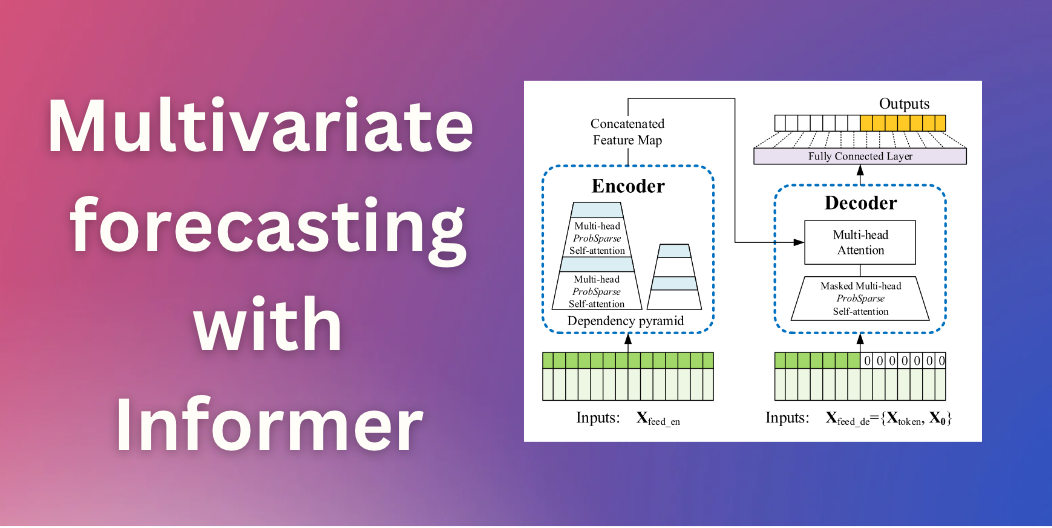
Open-sourcing Knowledge Distillation Code and Weights of SD-Small and SD-Tiny
Hugging Face has released the code and weights for SD-Small and SD-Tiny, two smaller versions of its Stable Diffusion model. These models were created using knowledge distillation, a technique that trains a smaller model to mimic the behavior of a larger one. The goal is to make powerful image generation models more accessible and efficient for researchers and developers. AI