SegmentAnyTreeV2: Scaling Transformer-Based Tree Instance Segmentation Across Sensors, Platforms, and Forests
Researchers have developed SegmentAnyTreeV2, a new framework for segmenting individual trees within forest point cloud data. This system utilizes a Point Transformer v3 backbone and a specialized mask decoder to achieve high accuracy in identifying and outlining trees, even in dense and complex environments. The accompanying FOR-instance v3 benchmark dataset includes over 26,000 annotated trees, enabling robust evaluation and demonstrating SegmentAnyTreeV2's superior performance and cross-domain generalization capabilities. AI
IMPACT Sets a new benchmark for tree instance segmentation in forestry, potentially improving ecological monitoring and resource management.


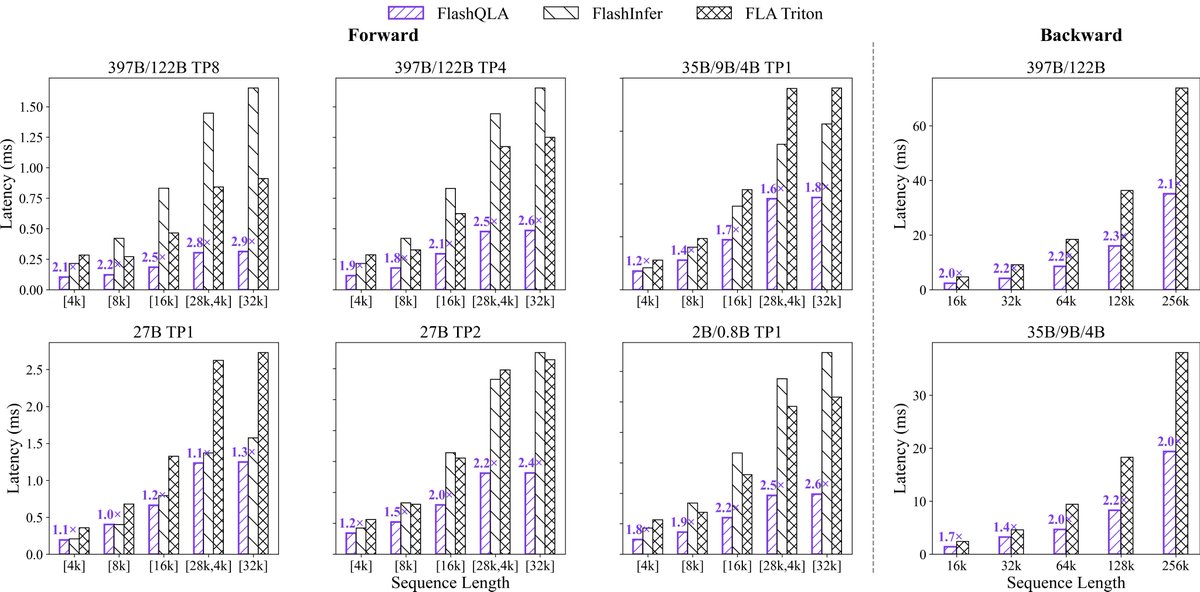
![[3090] Gemma4 QAT + MTP quick TPS numbers [TLDR 1.2-1.8x better]](https://preview.redd.it/sqcwpyzee26h1.png?width=140&height=36&auto=webp&s=aa35a209b2b7baa1197095070bb57c49327a1f08)