Meta-learning for wrestling
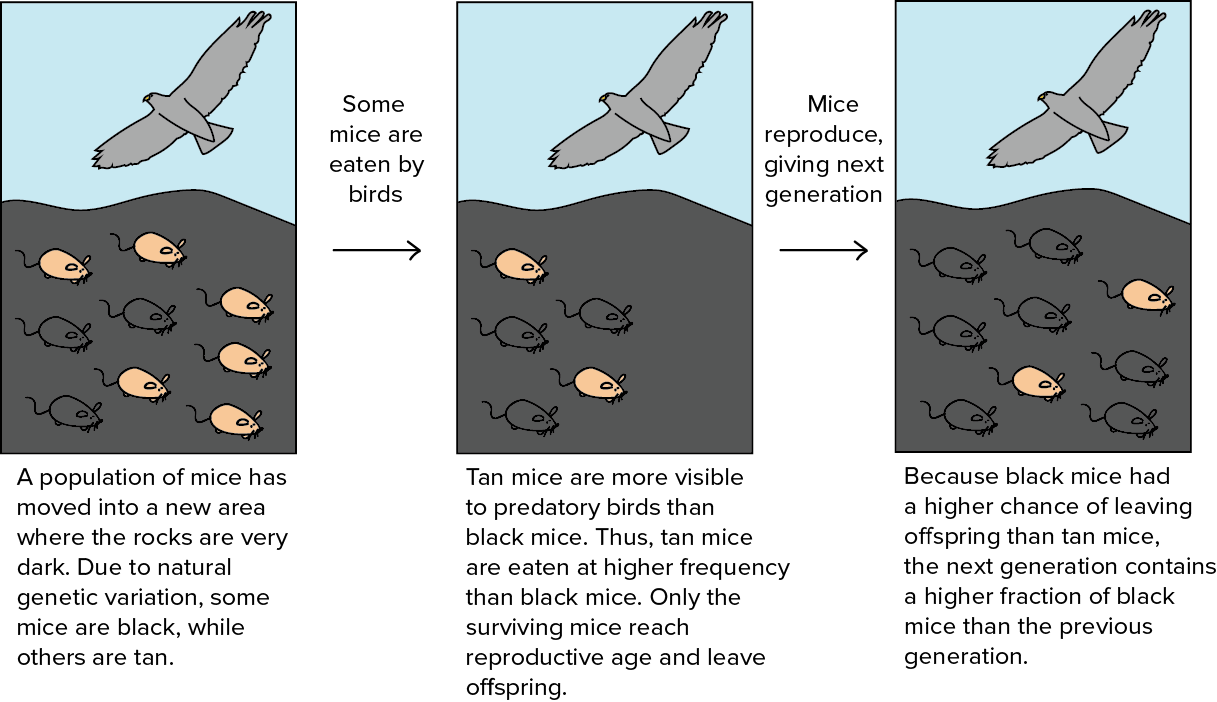
OpenAI researchers have developed a meta-learning agent capable of quickly adapting its strategy in simulated robot wrestling matches. This agent, an extension of the MAML algorithm, optimizes its objective function against pairs of environments to enable rapid learning in new situations. The meta-learning approach allows the agent not only to defeat stronger opponents but also to adapt to physical malfunctions, such as losing limbs, suggesting potential applications for agents that can handle both external environmental changes and internal bodily alterations. OpenAI is releasing the MuJoCo environments and trained policies to facilitate further research in this area. AI